データ活用を進める際にぶつかる3つの課題
ではまず、そもそも現状の課題整理からスタートしましょう。
データ活用自体は、もうかなり多くの企業で「取り組まないといけない課題」として挙げられるようになってきたように思います。本格的に社内でのデータ活用を進めるには、データ分析を専門に担当する部署に閉じるだけではなく、営業・企画・人事といった部署へと広げていくことになります。……となったときに、課題となってくるのが「データ管理の煩雑さ」です。組織のどこにどんなデータがあって、どう活用するのか、管理しないといけないけれど、それが大変、ってことですね。そしてもうひとつが、「データ連携の大変さ」。複数の部署、複数のシステムに散らばったデータを、どうやって連携するのか、といったところで、確かにこれもなかなかに厄介そうです。
ここまできたところで、次に出てくるのが「権限管理」の問題です。社内にあるデータを連携して、自由に使えるようになるのは便利ですが、「どのデータもだれでも使っていいよ」とするのはリスキー。人事データなど「限られた利用者が」「限られた用途で」使うべきデータもなかには含まれます。「データ活用を進めるには、データごとに制約をつけることが重要で、閲覧範囲を適切に設定できていないことが課題になる。一方で、細かく対応するために、多数のビューを作って、管理が煩雑になってしまうこともある」と。そして、粒度の細かい管理を、いかに簡単に実現するか、このバランスが重要になる……と。納得ではありますが、これまたハードルが高い気がしてなりません。
では、この3つの課題にどう対処するのか、それぞれの解決策を見ていきましょう。
どこに、どんなデータがあるのかを管理する「Amazon DataZone」
ではまず、データそのものの管理から。どこにどんなデータがあるか分からないなら、「メタデータ」を一元管理すればいいのだ!……ということで、発表されたばかりの新サービス「Amazon DataZone」の登場です。メタデータとは、どこにあるのか、どんなデータかなどデータを管理するための情報のこと。これらをまとめて「データカタログ」を実現して、一元的なデータガバナンスを実現するのが、Amazon DataZoneです。Amazon S3、Amazon Redshiftのほか、AWSの外にあるデータもあわせて、どこにどういうデータがあるかという、「カタログ」を作成し、GUIベースのポータルで検索できるようになるのだとか。確かにこれがあれば、どこにどんなデータがあるのか分からない問題はクリアできそうです。
Amazon DataZoneはAWS re:Invent 2022で発表され、Limited Previewとなっていたのですが、2023年3月29日にパブリックプレビューとなりました。今後、期待したいサービスのひとつと言えそうです。
Amazon Redshiftの「Data Sharing」機能で、データ連携を簡単に
続いて、データ連携の課題ですが、簡単に言えば、保管場所をまたいで自由にデータをやり取りできればいいワケです。まぁ、それを簡単に言うなよ……という話でもありますが、Amazon RedshiftのData Sharing機能を使えばできる、らしい。
Data Sharing機能は、Amazon Redshiftのクラスタ間でデータを共有するもので、簡単な設定をするだけで、Amazon Redshiftに置いたデータを違うクラスタから読めるようになるのだそう。ついでに「データそのものを移動しなくてよいので、セキュリティ上もメリットがある」と。確かに、データをほかのシステムでも参照したいとなったときには、データを該当システムから見えるところにコピーして使うこともありそうですが、となると、コピーした先のデータもちゃんと保護しなくてはならなくて、セキュリティ対策的に大変そう。データ自体を増やすことなく、他システムから参照することで、セキュリティ的にもヨシ、ということですね。
Amazon Redshift Data Sharingによるクラスタ間でのデータ共有
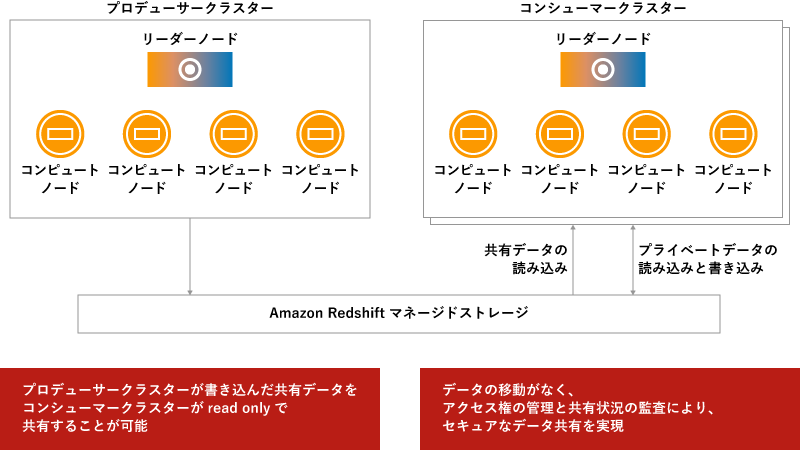
同じ会社の部署間でデータを連携するのはもちろんですが、アカウントやリージョンをまたいだ連携もできるので、他社とデータを連携することも可能です。
えっと、そもそもどちらもAmazon Redshiftを使っていないとダメなのでは……という大前提のところでつまずきそうな気持ちではありますが、逆に言えば、データ活用を進めるなら、Amazon RedshiftとかでDWHを構築しないとハナシにならないし、そこをクリアしてしまえば、ここまで便利に使えるのだよ、ということなのかなと。将来的な理想形のひとつとして、記憶に留めておきたいと思います。
Amazon Redshiftなら、細かい権限管理も簡単
さて、最後は権限管理です。「粒度の細かい管理を」「簡単に実現する」の2つがキーと上でも解説しましたが、要はそれもAmazon Redshiftでできますよ、って話ですね。
まずは「ダイナミックデータマスキング」という機能です。これは、「特定の条件を指定しながら、ユーザによって異なるデータが見えるようマスクできる」のだと。たとえば、ニューヨーク担当のアナリストは、ニューヨーク在住の顧客の個人情報は平文で参照できるけれど、ほかのエリアの顧客情報はマスクする、的なことができるようです。ほかにもデータを部分的にマスクしたり、「xxxxx」のような決まった文字列に置き換えるのではなくハッシュ化してマスクすることもできるのだとか。
もうひとつは、行レベルでのアクセスコントロールです。「顧客情報のなかでも、住所とメアドは見えないようにする」のが列レベルでの権限管理ですが、Amazon Redshiftでは行レベルでの権限管理にも対応できます。つまり、ユーザごとに「条件に合致した行しか閲覧できませんよ」という管理ができるということですね。
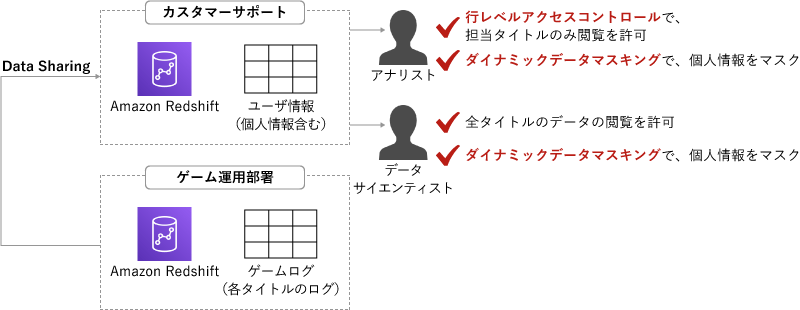
ここまで紹介してきたAmazon Redshiftの機能について、デモがありました。想定したのは複数のモバイルゲームアプリを運用している企業で、カスタマーサポートが持つユーザ情報と、ゲーム運用部署が持つゲームログを連携して、もっと活用しよう!ということです。
まずはData Sharingにより、両方のデータを連携。ゲームごとの動向などを分析するアナリストには、行レベルアクセスコントロールで担当タイトルのみの閲覧を許可します。一方、全タイトルのデータを用いて機械学習モデルの作成などを目指すデータサイエンティストには、全タイトルのデータ閲覧を許可。
どちらも、個人情報にはダイナミックデータマスキングを使ってマスクしておく、といった感じです。
ユーザ側は、SQLでデータにアクセスしても、Amazon SageMakerのNotebookからアクセスしても、この権限が反映されます。
行レベルアクセスコントロールも、データのマスキングも、SQL文を使って設定を作ったり紐づけたりしていて、データベースに慣れている人であれば、そう違和感はないのかなと思います。というか、ここで言われていた“簡単”とはそういう意味であり、SQLとかがまったく分からない人でもGUIでポチッとできるよ!ということではないようだ、というのを書いておきたいと思います。
デモで目指すデータガバナンス
データ活用では、「ガバナンスをどうするか」も要検討
今回のセッションは、最初にターゲットが示された段階でも思いましたが、初心者シイノキとしてみれば、最初に踏むべきステップをいくつかふっとばした状態でスタートしたようなもので、案の定「いきなりそんなこと言われても」感はありましたが、Amazon Redshiftのいろんな機能を知ることができたのはおもしろかったです。このセッションのポイントはとにかく、「データ活用にはデータの有用性と、ガバナンスの両立が求められる」ことと、あとは「Amazon Redshiftを活用すれば、データ連携から権限管理まで実現できる」ことの2つ。データ活用したい、そのためにデータ基盤を整えなきゃ、というときに、Amazon Redshiftは有力候補になるんでしょう。
近いうちに、今回すっ飛ばしてしまったデータ分析の基礎の基礎についても学んでいきたいと思います。以上、シイノキでした!