AI・ML、最初の一歩なら“画像・動画認識”がお勧め
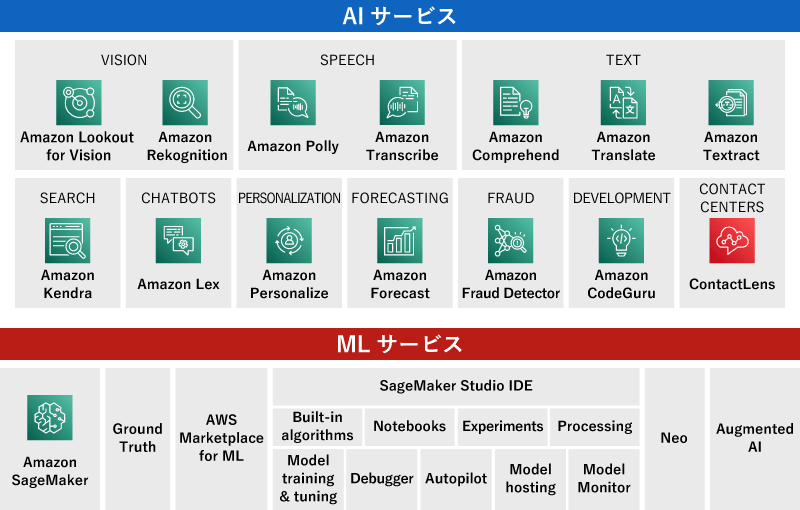
AI・MLと言っても、その幅はかなり広く、ジャンルもさまざまですが、AWSでは大きく「AIサービス」と「MLサービス」に分けてサービスを展開しています。
- AIサービス
チャットボットを実現する「Amazon Lex」や文字起こしをする「Amazon Transcribe」、予測分析が可能な「Amazon Forecast」などさまざまな用途にあわせたサービスを提供。「すぐに・だれでも・簡単に」使えるよう、学習済みのモデルを用意。 - MLサービス
Amazon SageMakerをベースとした機械学習(ML)モデルの開発基盤を提供。
これだけあれば、何かにすぐ使えるのでは……と思いたくなりますが、逆に「何からすればよいのか分からない」というのもよくある課題だそう。
セッションでは、「時間とコストが限られたなかで、もっとも効率がよいものを選ぶことを考えるとよい。最初にAIに取り組むなら、ユースケースが豊富で成果をイメージしやすい画像や動画の活用はお勧め」といった話がありました。
確かに「データからなにかを導く」となると、いろいろと知識やスキルが必要ですし、どのデータをベースとするのか、解析結果が正しいのかなど適切に判断するのもなかなか大変そうです。それに比べて、画像認識では「人が見れば分かる(判断できる)」ケースが多く、効果も見極めやすいような気がします。
AIを自社で使えるかどうか判断するための3要素
とはいえ、「AIを使えばなんでもできる!」かというと、残念ながらそこまでの進化は遂げていません。そこで、何ができるのか、実際に自社で“使える”かどうかの判断基準となる要素が紹介されていました。それは「ビジネスインパクトが大きいか」「データは入手しやすいか」「機械学習が適用しやすい問題設定か」の3つ。
コストをかけてAIを導入したのに、ビジネスへのインパクトが限定的……というのでは導入する価値が少なくなってしまいますし、どんなにやりたいことでもやっぱりデータがなければ難しいのもそりゃそうだという話です。
そして最後も大切な観点で、「明確にルールがある処理ならば、機械学習ではなくプログラミングした方がよいケースもある」というのは納得です。なんとなく新しい技術は使いたくなりますが、それ機械学習でやる必要ある?機械学習に向いてる?というのは忘れずに意識しないといけないですね。
このあたりを判断するにはもちろん経験や知識が必要ですが、「画像・動画認識」はまさに機械学習が得意な分野。AWSでは物体認証や顔認証などもサービスとして用意されているので、検証も比較的簡単です。「ユースケースも多く、学習済みのモデルが提供されており、事前に大量のデータを用意する必要がないので、すぐにはじめられる」とのこと。ほほぅ、ならばどれだけ簡単なのか気になるところ。となったところで、続いて具体的なサービスの説明がありました。
画像・動画から“一般的な物体”を検出する「Amazon Rekognition」でできること
今回のセッションでは、画像・動画認識系のサービスとして「Amazon Rekognition」と「Amazon Lookout for Vision」の2つが取り上げられていました。
まずは、Amazon Rekognitionですが、こちらは以前のコラムでも紹介していたサービスで、画像および動画から、一般的な物体を検出できるもの。9つの機能+利用者がカスタマイズできる「カスタムラベル」で構成されています。9つの機能は下記のとおり。
- シーン、物体検出:画像に写っている一般的な物(車、猫など)を検出
- 顔の検出と分析:画像に写っている顔を検出し、年齢や性別、顔の向きや感情などを分析
- 顔の検索と認証:顔を比較して、同一人物かどうかを類似度で判定。顔認証などに活用可能
- 有名人の認識:有名人が写っているかどうかを認識
- モデレーション:性的・暴力的なものなどが含まれているかどうかを検出
- テキスト検出:撮影した画像に移っているテキストを読み取り(日本語非対応)
- 動線の検出:動画から、特定の人などの動線をトラッキング
- メディア分析:動画からクレジットなどを検出、シーン検出も可能
- 保護具の検出:フェイスカバーやマスク、ハンドカバー(手袋)などを検出
ちなみに「一般的な物ってなにさ?」「有名人ってだれまで含まれるの?」というところは公開されておらず、「試してください」とのことでした。
そして、こういった一般的な物ではなく、なにか特定の物体やシーンを認識したいときに使うのが「Amazon Rekognition Custom Labels」です。自社製品が写っているかどうか、とかそういうことですね。このあたりのモデルも、認識したいモノが写っている写真を用意して、GUIツールでラベル付けしていくだけで、モデルをノーコードで構築できるのだとか。この機能を使うことで、たとえば「製品の傷にラベルを付け、画像から傷がついた製品のみ特定する」といった外観検査もできる、とのこと。
「簡単に」という言葉には騙されないぞ、という気持ちはありますが、これまでと比べて画像・動画認識のハードルがさらに下がっているのは間違いないでしょう。
外観検査に特化した「Amazon Lookout for Vision」とは?
「Amazon Rekognition Custom Labels」を使えば外観検査もできる……となったばかりですが、続いて紹介された「Amazon Lookout for Vision」は外観検査に特化していて、さらに簡単に実現できる、というものです。外観検査とは、製造工程などで製品の外観に傷や汚れ、変形などがないかをチェックすること。従来は人が目で見て確認する方法が主流でしたが、これをAIで実現しちゃおう……というワケですね。
そのメリットとしては、「外観検査では、学習用教師データとして異常な状態の画像を大量に用意するのが難しいことがネックだったが、Amazon Lookout for Visionでは正常な画像を20枚、異常な画像を10枚以上用意すれば、正常か異常かを判断できる」といった説明がありました。確かに、AIでは学習用データを事前にたくさん用意しなければならない、というのが基本とされていますが、「製品の正しい状態の画像」は用意できても、さまざまな傷や汚れなど異常パターンの画像を用意するのは大変そうです。これが10枚で本当に異常を検知できるようになるなら、それはすごいのでは……?ちなみにもちろん、判断の結果が間違っていれば、それを指摘することで、AIが再学習して、どんどん精度があがっていくことに。また、検査結果を確認できるグラフィカルなダッシュボードも提供されているそうです。
画像・動画認識系AIユースケースのチェックポイント
最後に、ユースケースをチェックする際のチェックポイントについても紹介されていたので、まとめておきます。画像・動画認識系のAIではさまざまなユースケースや事例が紹介されていますが、自社導入を検討するときに、どんなポイントを確認すべきか、ということですね。そのポイントは、下記の6つ。
- データの種類・被写体
- 問題設定
- 画像データの取得条件
- 使用したサービス
- 画像認識後のアクション
- ビジネスインパクト
言われてみれば当たり前のポイントではありますが、実際自社で導入するとしたらどうなるだろうかを踏まえてユースケースを見ることで、「どれくらい実現できそうか」「実は無理なのでは」といった基準にもできそうです。
機械学習やAIを活用する企業は増えたものの、実際ビジネスの現場ですぐ使えるかというとまだハードルが多いように思っていましたが、画像・動画認識のAIならば、活用シーンも多いのではないかと感じました。データサイエンスの専門知識がなくても導入しやすそうですし、最初の一歩としては有効と言えそうです。