Amazon Lexの仕組み
最初に、Amazon Lexの仕組みをおさらいしておきます。音声認識や言語理解などにより、会話型のチャットボットを作成できるサービスです。つまり、ホテル予約のチャットボットだと、下記のようなイメージ。
Amazon Lexによるチャットボットイメージ
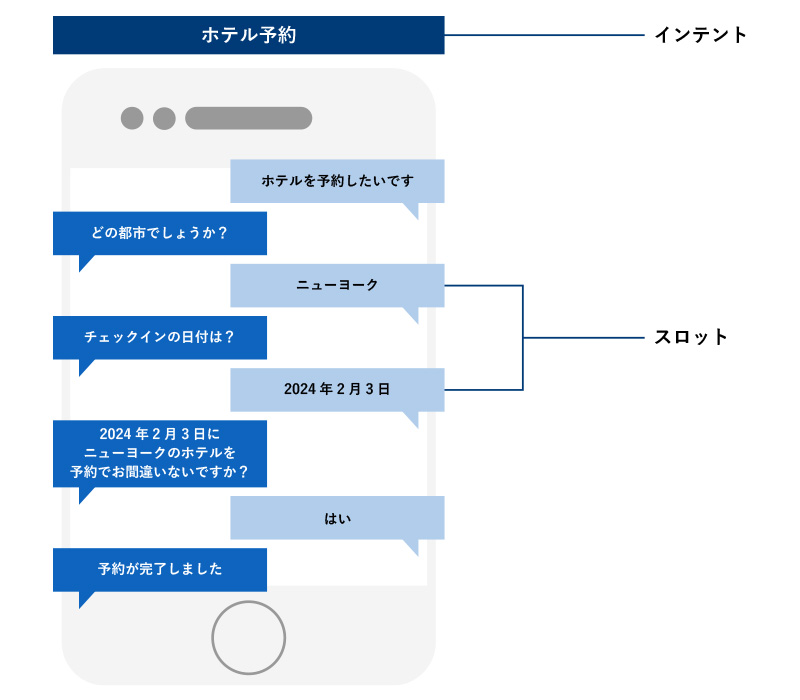
まぁ、実際ホテル予約するとしたら、もうちょっと項目が必要になりますが、そうしたらやり取りが増えていく形です。
で、ここで、ポイントになるのが「インテント」と「スロット」という2つの要素です。「インテント」はユーザの目的、つまりこれが「なんのボットか」ということです。上記のボットの場合は、「ホテル予約」です。
そして「スロット」は、目的達成に必要な情報のこと。「都市」「予約日」「人数」など、ユーザから聞き出す必要がある情報を指します。
当然と言えば当然ですが、チャットボット作成時に、これらを自分で設定する必要があります。
生成系AIで改善した3つのポイント
では上記を踏まえて、生成系AIによりなにが改善したのかを見ていきます。ポイントは3つです。
<改善ポイント 1>スロットの値を文脈から理解してくれる
スロットになんの値を入れるかは、チャットボットがユーザの回答から判断するわけですが、たとえば「何人で予約しますか?」という問いに対して、「自分と友人、あとその子どもが2人きます」などと回答されるケース、あり得ますよね。これまでのAmazon Lexはここから「4人」ということが理解できなかったのですが、生成系AIが入ったことで「4人」だと判断できるようになりました。
おそらく実際に作り込むときには、そのあとで「4人でOKですか?」と確認する流れを取ったりするのかなと思いますが(漠然と抱えてしまう不安感)、ますます自然な会話に近づくのではないでしょうか。
<改善ポイント 2>自然言語でボットを構築できるようになる
……と言われてもなんのことだか、という感じですが、要するにスロットをひとつずつ人が設定するのではなく、「こういうボットを作りたい」と文章でまとめて記述するだけで、インテントやスロットを自動設定してくれるのだと。
たとえば、「私は旅行代理店で、アミューズメントパークへの旅行を予約するボットを考えています。アミューズメント施設とあわせて、ホテルやレストラン、スペシャルイベントの予約もできます。ボットユーザは予約を変更・キャンセルできる必要があります。予約には少なくとも日付、ホテルを含める必要があり、食事やイベントはオプションです。後から追加変更できます」と文章を書くと、いい感じでボットを作ってくれる、ということです。
これ……打つのも面倒では……?と、今まさに文章を入力しながら思わないでもないのですが、ここから「適切なスロットを設定する」となると、一段ハードルが上がるのは事実。チャットボット作成のハードルを大きく下げるよ、という効果は十分期待できそうです。
<改善ポイント 3>発話サンプルを自動生成
発話サンプル、つまり「こういう発言がきたら、このインテントです」というサンプルですが、これまではインテントを作成するときに、手動で設定する必要がありました。例としては
発話サンプル例

のように列挙していく感じ。{}で囲っているところは、具体的なピザの種類やサイズが入ることを示していて、「{pizzaKind}ピザをください」で「マルゲリータピザをください」のような発言に対応できる、というイメージです。
想定されるバリエーション全部手動で設定するのかと考えると、ちょっと気が遠くなりそうですが、このサンプルを生成系AIが自動でやってくれると。それは分かりやすく便利そうです!
AWSの生成系AIはなにを目指すのか?
今回はAmazon Lexの生成系AIによる進化にフォーカスしてご紹介しました。生成系AIというと、「なにか質問すると、その答えを文章で教えてくれる」というChatGPTのようなイメージが強いのですが、おそらくそれだけが本質ではなく、もっと業務のなかに入り込んで使っていくものなんだろうなとうっすら想像していました。Amazon Lexの進化はまさにその一例としてイメージしやすいものでした。
では、AWSは実際、生成系AIにどう取り組んできて、どんな未来を描いているのでしょうか?AWS re:Invent 2023報告会での濱田さんのお話を少しまとめてご紹介します。
「AWSのAI最高責任者である、Dr. Swamiの基調講演を聞きましたが、生成系AIの課題としてよく挙げられるハルシネーション(※)、プライバシー、データの鮮度、機密情報の取扱い、利用者特性について的確にアップデートを実施しているというメッセージがありました。
AWSは先を見据えた取り組みが多いですが、今回はまさにそれを実感しました。どういうことかというと、2023年のテーマは『生成系AIの民主化』でしたが、2022年は『データの民主化』で、だれでも簡単にデータを活用できるようにするためのアップデートが数多くなされました。AI活用のためには、データがないとはじまりませんから、AIの民主化をするためには、だれでもデータを使えるようにしておく必要があるんですよね。かなり前から生成系AIの民主化というテーマまでを見据えて、戦略的にサービスを作ってきたのだと理解しました」
では、ここからどうなっていくのでしょう?
「生成系AIはトレーニングに使われているドキュメントが欧米中心のため、ビジネスマナーについて聞くと欧米でのマナーをベースとした回答が返ってきます。この状況から脱し、文化を理解することを目指す、としていました。それによって、世界中でより深く生活に浸透していくのではないでしょうか」
確かに、生成系AIでは「英語で質問した方が、精度が高い」といった話も聞かれます。ここを乗り越えてくると、また関わり方が変わってくるのかもしれません。
「開発者の生産性もあがるでしょうし、教育もどんどん進化していくでしょう。技術を活用する教育をしなければ追いつかなくなるはずです。生成系AIはこれから“だれもが使って当たり前”の技術になると思います。もちろん、「生成系AIさえ使えばなんでもできる」というわけではありませんが、今までできなかったことができたり、ラクになったりしていくでしょう。ソニービズネットワークスでも、Amazon GuardDutyの検出結果を、Amazon Bedrockで分かりやすい文章に変換して通知する、といったソリューションの提供を開始しましたが、これからも新しい技術をしっかり取り入れて、いろいろ取り組んでいきたいと思います」
生成系AI、自分が書く文章が影響を受けてしまいそうで、時々そっと使う程度に留めてきたのですが、もうちょっと踏み込んで使わないといけなそうだな、と感じました。決して調べものをするだけのものではなく、仕事を効率化できるなにかがあるはずです。具体的になにができるのかを考えて、手ごたえを得られる1年になったらいいな(希望的観測)と思います。以上、シイノキでした!