「生成系AI」とはなにか?
Amazon Bedrockの説明に入る前に、まずはここからです。なんとなく分かったつもりで話しているけれども、そもそも「生成系AI」とはどういうものなのでしょうか?AWSとしては下記のように定義しているとのこと。
- 一般的に「基盤モデル(Foundation Model)」と呼ばれる、膨大なデータに基づいて、事前にトレーニングされた大規模モデルを利用
- 会話やストーリー、画像、動画、音楽など、新しいコンテンツやアイデアを創造する
ポイントとしては、コンテンツを生成するために必要な学習・トレーニングが完了した状態のモデルを使うので、すぐに利用できる……というところでしょう。背景にあるのは、膨大なデータを学習できるようになったこと、そして計算能力も大きく向上したこと。そこに機械学習の進化が重なり、画像生成AIの「Stable Diffusion」や「Midjourney」、テキスト生成AIの「ChatGPT」などは、登場とともに一気に注目を集めました。そして、生成系AIをビジネスに活用することで、顧客体験の向上や生産性向上、事業運営改善などさまざまなメリットがあるのではと期待されている、というワケです。
ちなみに、これまでのAIとの違いについては、AWSのセッションで、こんな説明がされていました。
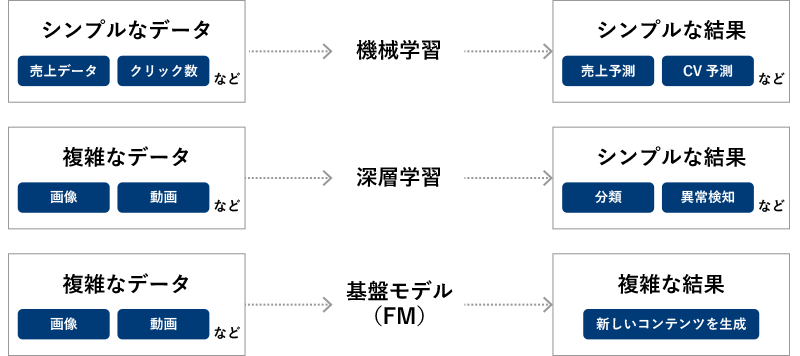
- 従来の機械学習は、シンプルなデータ(数字など)から、シンプルな結果を出力する。売上などのデータをもとに、売上予測のデータを出す、といったイメージ
- 深層学習(ディープラーニング)は、複雑なデータ(画像・動画・テキストなど)から、シンプルな結果を出力する。要は「猫の写真」を学習させて、「猫」を判断できるようになる、という感じ
- 生成系AIは、複雑なデータ(画像・動画・テキストなど)を学習し、複雑な結果を出力できるようになった
ということだと。これでようやく、とっかかりを掴めた……ような気がします。
これまでのAIとの違い
「Amazon Bedrock」とは?
さて、Amazon Bedrockは、生成系AIアプリケーションの構築に使える、フルマネージド型サービスです。……どういうこと?という感じですが、要するに、生成系AIで使う基盤モデル(Foundation Model)がいろいろと用意されていて、それをAPIで簡単に使えるようにしてあるよ、ということの様子。基盤モデルはAmazonの生成系AI「Amazon Titan」を含め6種類を提供(2023年11月6日現在)。それぞれ得意分野が異なるので、用途に応じてマッチするものを選ぶことができます。
Amazon Bedrockが提供する基盤モデル

もうひとつ、大きなポイントとして、「自分たちのデータを使って、基盤モデルをカスタマイズできる」ことがあります。当然と言えば当然ですが、生成系AIをビジネスに使うとなると、AIにも自社のことを学んでもらう必要があります。あくまでたとえですが、「生成系AIで、社内向けチャットボットを作り、社内規定などについての問い合わせに回答させたい」となったら、社内規定などの情報を覚えてもらわないといけないわけです。で、基盤モデルをカスタマイズしなければならない、と。Amazon Bedrockではこれにも対応できて、しかももちろん自社のデータについては、VPCを離れることがなく、データのセキュリティが守られる、とのことでした。
「Amazon Bedrock」のメリット
なんとなくできることが分かってきたところで、Amazon Bedrockのメリットについてまとめていきましょう。
インフラの管理が不要
またそれか……という感じではありますが、AIだと余計にインフラ管理は大変そうですし、大事なポイントですよね。インフラのことを考えずに運用できるのは便利です。
複数の基盤モデルや、新しいバージョンも簡単に利用可能
Amazon Bedrockでは6種類の基盤モデルが使える、と紹介したように、複数のモデルを簡単に使うことができます。「自社の用途にあわせて選びましょう」と言われても、どれがいいのか使いながら探っていくのに、基盤モデルごとに環境を作って、使えるように整えて……とするのはかなり手間!バージョン管理も面倒くさい!そのなかで、決まったAPIで複数の基盤モデルを使えるのは、大きなメリットと言えそうです。
既存システムとの連携も容易
ビジネスで利用するとなると、「生成系AIでなにかを出力するだけ」ではなくて、前後で既存システムと連携しなければいけないケースも多くなります。こういったニーズにも対応する機能が提供されていて、まずある処理を実行してから、生成系AIでなにかを出力、それをもとに次の処理……といった複雑なタスクも実現できるのだとか。
生成系AIは“ウソをつく”問題は、どうするのか?
最後に気になるのがここです。「ウソをつく」というと、少し大げさではありますが、回答の信頼性をどう担保するのかは大きな問題のはず。
実際、私自身も生成系AIを試してみたことはありますが、「完全に間違いではないけれども、正しいとも言えない」内容だったり、「押さえるべきポイントを微妙に外している」内容だったりと、このままでは仕事では使えないな、という印象でした。
こういった「AIが、真偽が分からない情報を、あたかも正しいかのように生成してくること」を「ハルシネーション」と呼ぶのだそうで、これをいかに抑制するかは生成系AI活用における大きな課題。
これを解消する方法が、RAG(Retrieval Augmented Generation、拡張検索生成)というアプローチです。要は、生成系AIを「質問に回答する」ものとして使うのではなく、まずは検索エンジンで検索し、ヒットした「正しいと思われる情報」を要約する用途で使う、ということ。AWSだと、Amazon Bedrockにエンタープライズ検索エンジン「Amazon Kendra」を連携することで実現できるのだとか。まずはAmazon Kendraで社内の情報を検索し、出てきた文書をAmazon Bedrockで要約して、回答として返す……という。それ、どんなメリットが?という気はしますが、質問をする人としては、「ここに書いてありますよ」という資料やサイトを開いて、ひとつずつ読んでいく必要がなくなり、最初から必要なところが要約された状態で回答を得られるようになる、と理解しました。
アイデア次第で、可能性は大きい「生成系AI」
生成系AI、気にはなるけれども、ビジネスで使えるかどうかは未知数すぎる……と思い、なんとなく遠巻きに眺めていましたが、今回学んだ結果、どうももっといろいろできそうだぞ、使い方次第ではかなり実際の業務でも便利になるのでは?と思いました。
アイデア次第でかなりいろいろ使えそう!というまとめではあるのですが、逆に言えば、アイデアがなければなににもつながらないのも、それはそう……。具体的になににどう使えて、どんなことができるわけ?というところで、次回は生成系AIのユースケースを取り上げたいと思います。以上、シイノキでした!