AWS Incident Managerとは
AWS Systems Manager Incident Managerは、インシデント対応プロセス全体を自動化するサービスです。Systems Managerファミリーの一部として、
運用管理の包括的なソリューションを提供します。
主な特徴として、事前定義された対応計画(Response Plan)に基づく自動インシデント作成、階層化されたエスカレーション機能、
そしてSlackやMicrosoft Teamsとの連携によるリアルタイムコミュニケーションがあります。これにより、人的ミスを減らし、対応時間を大幅に短縮できます。
従来の手動対応では、アラート検知から担当者への連絡まで数十分かかることも珍しくありませんでした。Incident Managerを活用することで、この時間を数分以内に短縮し、さらに対応手順の標準化により品質の向上も実現できます。
代表機能の詳細解説
Response Plan(対応計画)
Response Planは、インシデントタイプごとに事前定義された対応手順のテンプレートです。重要度レベル、エンゲージメント、実行すべき自動化アクションなどを設定できます。
例えば、Webサイトの応答時間悪化を検知した場合のResponse Planでは、以下のような設定が可能です:
- 重要度:High
- 初期対応者:Webチーム
- 自動アクション:Systems Manager Automationを通じたAuto Scalingグループのスケールアウト
- エスカレーション:15分以内に応答がない場合、マネージャーに通知
この仕組みにより、インシデントの性質に応じた適切な対応を自動的に開始できます。
Contact(連絡先管理)
Contactは、オンコール体制を管理する機能です。個人やチームの連絡先情報、対応可能時間、エスカレーション階層を定義できます。
SMS、音声通話、メール、Slackなど複数の通知チャネルを組み合わせることで、確実な連絡を実現します。
特に重要なのは、段階的エスカレーション機能です。初期対応者が一定時間内に応答しない場合、自動的に上位者や代替担当者に通知がエスカレーションされます。これにより、深夜や休日でも適切な対応者を確保できます。
Engagement(関係者招集)
Engagementは、「どの担当者やチームを、どの順番で、どの方法で呼び出すか」を定義する仕組みです。実際には、対応プランの中でコンタクトやエスカレーションプランを紐づけます。
これにより、情報の散在を防ぎ、すべての関係者が同じ情報を共有しながら協力して問題解決に取り組めます。また、対応履歴も自動的に記録されるため、事後の振り返りや改善活動にも活用できます。
実践的な活用例
実際の運用では、CloudWatchアラームとの連携が最も一般的なパターンです。例えば、EC2インスタンスのCPU使用率が90%を超えた場合の対応フロー
は以下のようになります:
- CloudWatchアラームが発火
- Incident Managerが自動的にインシデントを作成
- 事前定義されたResponse Planに基づき、インフラチームに通知
- Slackに専用チャネルが作成され、関係者が招集
- 必要に応じて自動スケーリングやインスタンス再起動を実行
- 15分以内に解決しない場合、マネージャーにエスカレーション
このような自動化により、一般的に初期対応時間を大幅に短縮できます。
また、AWS Lambda、Systems Manager Automation、EventBridgeとの連携により、より高度な自動修復も可能です。
例えば、データベース接続エラーを検知した際に、自動的に接続プールをリセットし、それでも解決しない場合にのみ人的対応を要求するといった段階的な対応も実現できます。
やってみた
今回は、EC2インスタンスのCPU使用率が90%を超えた場合に、SSMドキュメントを実行してEC2を再起動し、一次対応を行いメール通知も行うという内容で検証してみました。CloudWatchアラームは事前に設定をしております。
対応プラン、エスカレーションプラン、コンタクトの作成
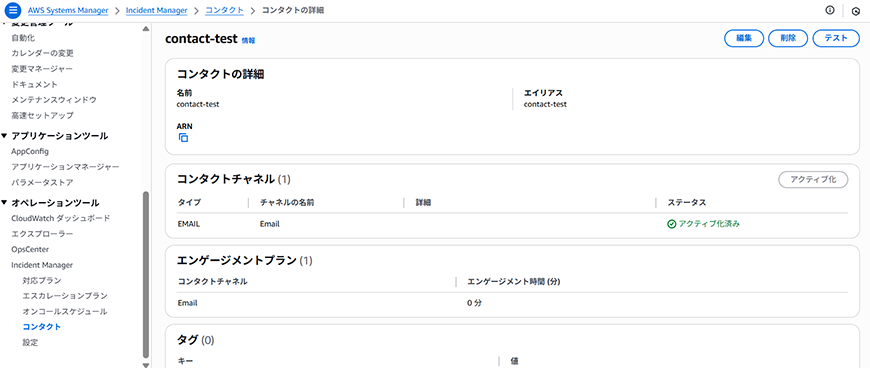
まず、コンタクトの作成を行います。
コンタクトはインシデントが起きた際に誰に連絡するかを設定する箇所となります。
今回は検証となりますので、私自身のメールアドレスを設定しております。
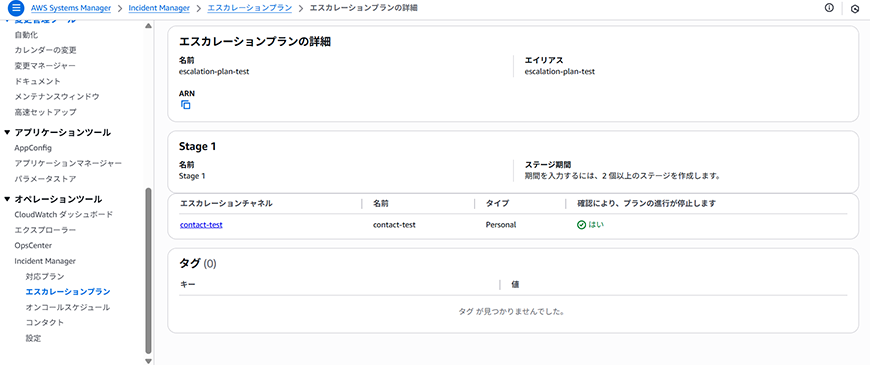
次にエスカレーションプランを作成します。
ここでは、インシデント発生時に先ほど作成したコンタクトや今回は設定しておりませんが、オンコールスケジュールを基に、段階的に対応者を拡大していく設定です。例えば、初期対応者が一定時間内に応答しない場合、自動的に上位者や代替担当者に通知をエスカレーションするといった設定です。
今回は、先ほど作成したコンタクトを選択しております。
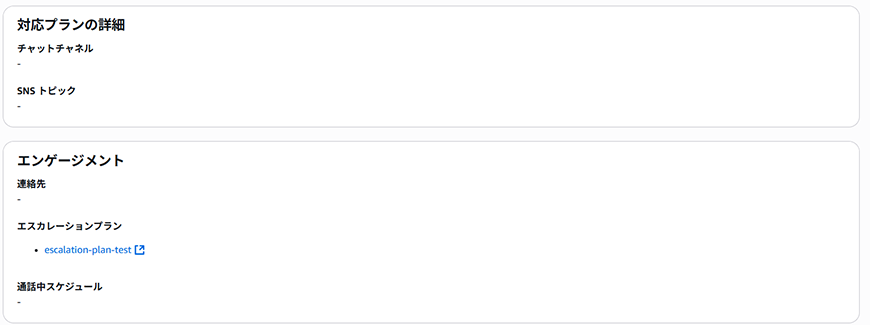
上記完了後、対応プランを作成します。
対応プランは、インシデント発生時に何を準備する必要があるかを定義するプランです。
エンゲージメントには、エスカレーションプランで作成したプランを付けております。
ランブックは、後で設定するのでここでは空にしております。

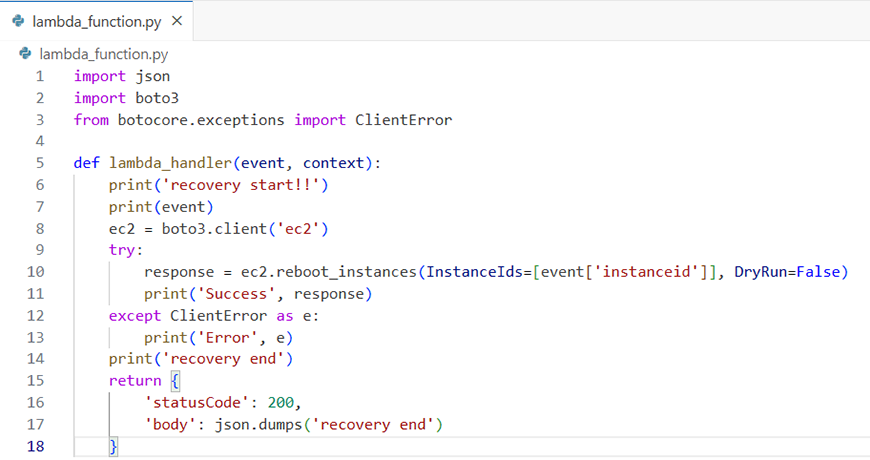
Lambdaの作成(EC2再起動)
次は、インシデントが起きた際にEC2を再起動を行うためのLambdaを作成します。
ソースコードは下記です。
SSMドキュメントの作成
Lambdaの作成完了後にSSMドキュメントの作成をしていきます。
ドキュメントの内容は、インシデント発生のインスタンスIDを取得して、Lambdaを呼び出すといった内容になります。
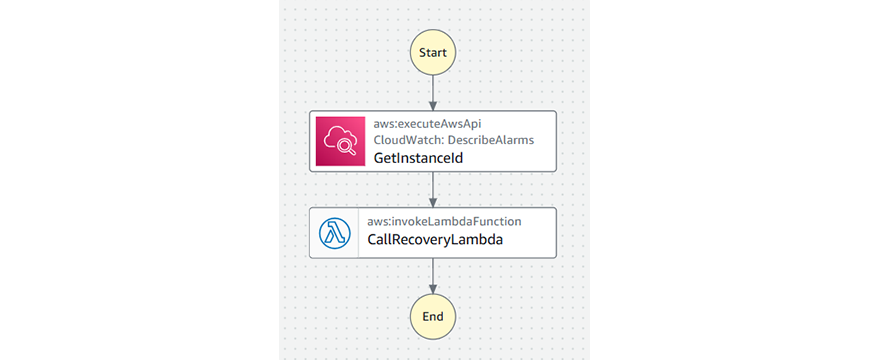
SSMドキュメント作成後、対応プランに作成したSSMドキュメントを紐づけます。
検証
下記コマンドを打ちサーバにストレスをかけます。
sudo dnf install -y stress-ng sudo stress-ng --cpu "$(nproc)" --cpu-load 90 --timeout 10m --metrics-brief
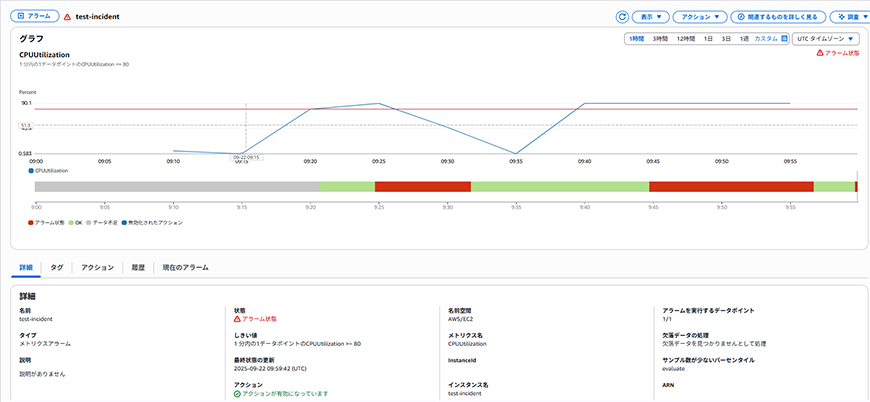
コマンド実行後を数分でCloudWatchにアラームが出力されています。
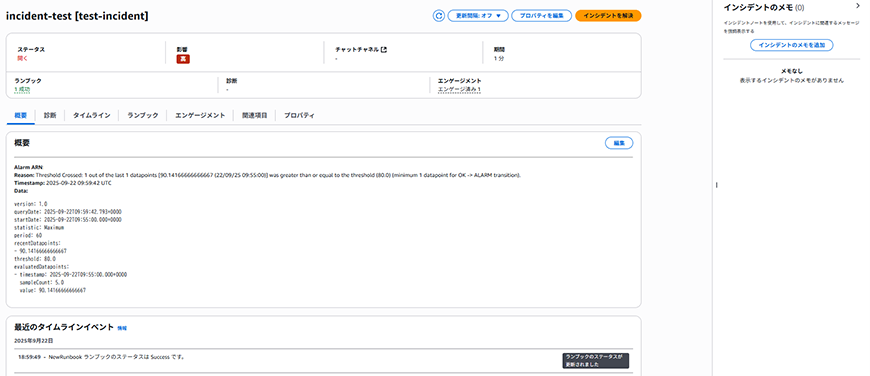
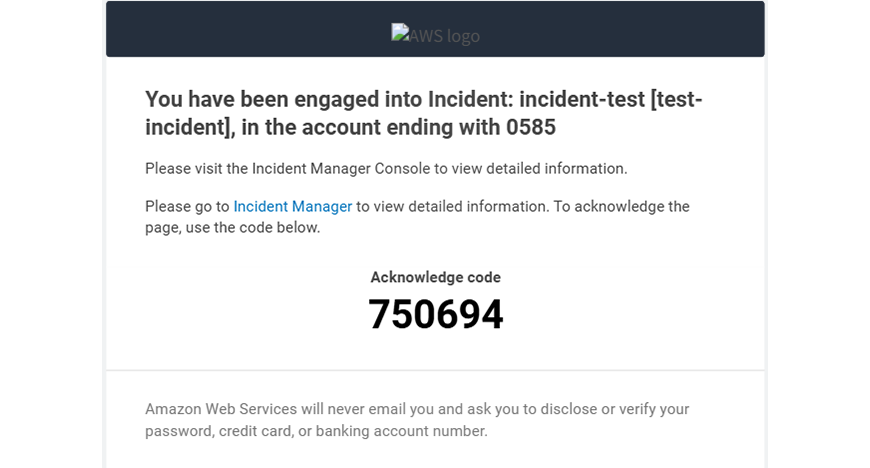
そして、Incident Managerを確認すると、インシデントが発行されており、概要やタイムラインイベント、診断等が見れました。
メールでの通知も確認することができました。
まとめ
AWS Systems Manager Incident Managerは、インシデント対応の自動化と標準化を通じて、運用効率の大幅な向上を実現します。手動対応による遅
延やミスを削減し、組織全体の可用性向上に貢献するのに有用なツールです。
クラウドの活用が当たり前になった今、Incident Manager のような自動化ツールをうまく使えるかどうかが、他社との差につながります。
きちんとした導入計画を立てて、段階的に取り入れていけば、組織全体のインシデント対応力を大きく高めることができます。
気になった方はぜひ利用してみてください。