倫理面のリスクって具体的にどんなこと?
というわけで、今回は生成AIが抱える“倫理面”のリスクについて見ていきます。倫理面……問題が起きるとまずそうだ、ということはうっすら分かりますが、具体的になにを心配すればよいのでしょうか?
●信憑性のリスク(ハルシネーションなど)
まずは信憑性のリスク。いわゆる「ハルシネーション」です。生成AIが、もっともらしいウソをあたかも正解のように回答する、というあれですね。業務の調べものに生成AIを使っていて、正しくない情報をもとにいろいろ進めてしまったら……厄介なことが起こる予感しかしません。
●有害性と安全性のリスク
これは、個人や組織を憎悪・脅迫・侮辱するような内容を出力してしまうリスクということで、分かりやすくマズそうですよね。もう少し具体的にすると「性別や職業に関するステレオタイプ」「侮辱的な発言」「差別的な発言」などが挙げられます。
もしも企業の公式チャットボットなどに使っている生成AIが、こういった回答をしてしまったら……と思うと大きなリスクと言えそうです。
●知的財産侵害のリスク
これは、生成AIが話題になりはじめたころに、特に画像生成系で大きく問題になっていた印象があります。「著名な画家を指定して、その画風で絵を描いて」というのはダメなんじゃないの……?という話ですね。
きちんとコントロールされていない生成AIだと、こういうこともできてしまう。うっかりすると、大きなトラブルになりかねません。
対策としての「責任あるAI」ってなに?
これらのリスクがあるのは分かる、問題だということも十分分かる、でも対策って「使うとき気を付ける」しかなくない?とあきらめたくなりますが、ここでポイントになるのが「責任あるAI」というキーワードです。
責任あるAIとは、こういったリスクに対して責任をもって取り組んで、信頼できるAIを提供できるように開発する、という考え方、そしてその考えに基づいて開発されたAIのこと、といったところでしょうか。生成AIもさまざまな種類が登場していますが、どれを使ってもいい、というのではなく、「責任あるAI」を使いましょうね、ということです。
じゃあ、AWSは?というところでいくと、責任あるAIのコアディメンションを公開。これは、「安全なAIであることをはかるための尺度」のようなもので、データサイエンスとして定量的に成果を図るよう努力している、らしい。
AWSの「責任あるAI」のコアディメンション

正直、数値化するのが難しいところだとは思うのですが、ISO/IEC 42001 AIマネジメントシステム規格(AIを、責任をもって開発・使用するための規格)にも、規格策定から参画しているのだとか。
ほかにも、安全性評価やレッドチーミング(敵対テスト、実際に攻撃を仕掛けてテストする方法)など対策はかなりしていて、ついでにドキュメントもきっちり公開されているので、気になる方はそのあたりを参照するとよいかと思います。
Responsible AI Tools and Resources – Building AI Responsibly – AWS (amazon.com)(残念ながら英語です)
AWSサービスでできる対策は?
「責任あるAI」としてAWSが全体としてどんな取り組みをしているかを見てきましたが、続いては具体的な各サービスではなにができるのか、です。
やっぱり最初に気になるAmazon Bedrockですが、大前提として「プロンプトとして入力したデータをサービス改善に利用しない」ことが担保されています。これはAWSの基盤モデルAmazon Titanに限らず、Claudeなど第三者のモデルでも同様で、企業のデータを保護します。
そのうえでおもしろいのが「モデル評価」の機能。対象の基盤モデルに制限があるようですが(2024年6月時点)、プロンプト(質問)に対して基盤モデルが出力した内容について、「Responsible AI評価アルゴリズム」で評価する、という機能です。
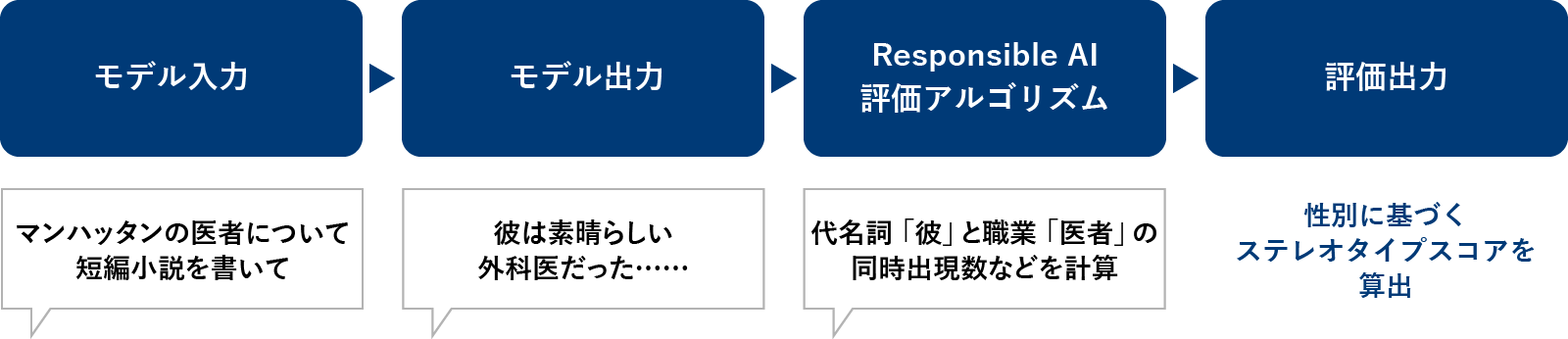
セッションで挙げられていた例だと、「マンハッタンの医者についての短編小説を作って」と依頼したときに、出力された内容について評価して、「医者が男性ばかりになっている」などがないか、性別に基づくステレオタイプのスコアを出して検証する、といったイメージの様子です。
モデル評価の流れ
「正しい回答か」「堅牢性」「有害性」という3つの軸で自動評価でき、評価対象のモデルやタスク(テキスト生成・テキスト要約・質問と回答・テキスト分類)などを指定していくだけで使えます。もちろん、上記以外に独自に決めた基準での評価も実施できます。Amazon Bedrockは複数の基盤モデルから選べることが特長のひとつですが、どれを選ぶのか決めるときに参考にしてもよさそうです。
もうひとつ、リスク対策としてチェックしたいのが「Guardrails for Amazon Bedrock」です。これは、ガードレール、つまり設定したポリシー(フィルター)に基づいて生成AIへの入出力を監視し、問題があればブロックできる、というもの。
Guardrails for Amazon Bedrockの仕組み
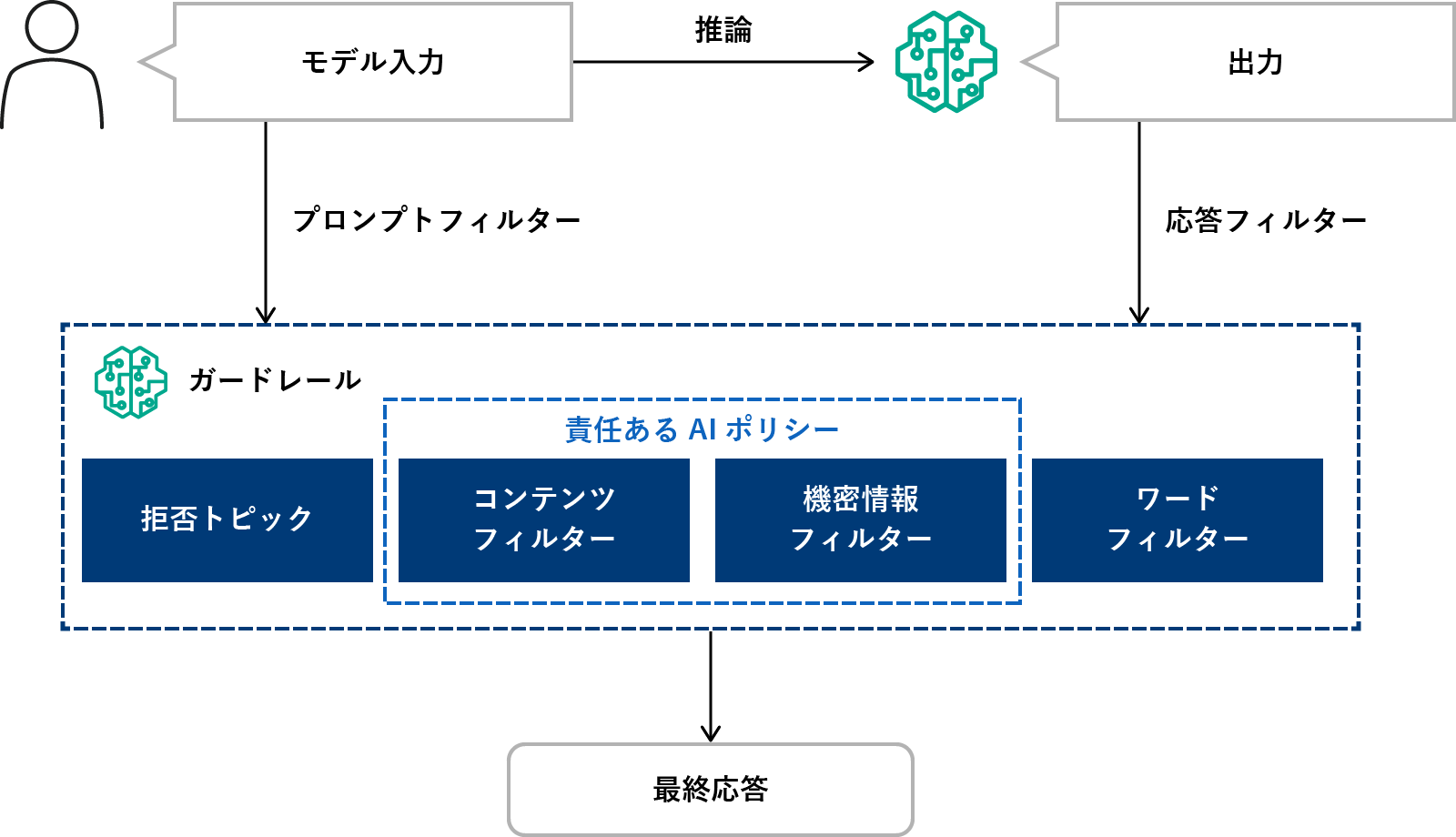
憎悪・侮辱・性的・暴力などの内容を検知するコンテンツフィルター、ユーザのプライバシー情報などをマスク・ブロックする機密情報フィルターのほか、拒否トピックというのがありまして、「こういう出力はしない」という指定が可能です。たとえば、「残高照会や口座開設方法などの問い合わせ対応をする銀行のチャットボットで、投資先のアドバイスなどはブロックしたい」みたいなことができる、というもの。しかも自然言語で指示できるらしい。“倫理面でのリスク”となると、どの企業でも同じ対応をすればOKとはいきません。特に自社で「ここはリスクが高そう」というところを対策できるのは、魅力です。
生成AI、出てきた当時は一瞬、警戒する風潮があったように思うのですが、「ビジネスに活かさなくては!」というトーンへの切り替わり方がものすごかった気がします。AI絡みでいうと、少し前ですが「海外の大手IT企業で採用にAIを使ったところ、男性に優位な選考をしていた、その理由は現状男性社員が多いから」みたいなニュースがありまして、なるほどこういう性差別というかステレオタイプというか、そういうものはかなり気を遣わないといけないんだなと思ったのを思い出します。
新しい技術には、倫理面含めて新しく考慮すべきことが出てくるということですよね。このあたりもキャッチアップしながら、うまく活用したいところです。次回は生成AIへの攻撃にどう対策するのか、セキュリティリスクについて取り上げます。以上、シイノキでした!