データ分析基盤とはなにか?
そもそもですね、「データ活用基盤」なの?「データ分析基盤」なの?という疑問からスタートしたい気持ちもあるのですが、ざっくり調べた限り、大きな違いはない、という印象です。言葉だけを見ると、データ活用の方が幅広い領域を指すように思いますが、現状だとデータ活用が指すのはほぼデータ分析。なので、データ活用=分析をするための基盤という認識で、ここでは「データ分析基盤」という言葉を使っていきたいと思います。
というわけで「データ分析基盤」ですが、これは、さまざまなデータを収集・蓄積・加工し、分析までをまとめておこなうための基盤のことを指します。
で、なぜこういった基盤が必要となるのかというと、その背景にあるのは、「データソースの増加」。データソース、つまりデータ分析の対象となるデータたちですが、以前は業務システムのデータベース程度だったのが、最近ではSaaSにもデータがあるし、モバイルのデータもあるし、動画やテキスト、さらにはIoTデータなど、どんどんデータが増える一方。しかもフォーマットもバラバラです。つまり、いろいろなデータが、いろいろな形式で、いろいろな場所に、膨大に保存されている状況だということ。
これだけデータがあるんだから、データをビジネスに活かしたい、となるのも当然の流れ。たとえば、なんらかの意思決定をおこなう際に、経験や勘をもとにするのではなく、データをもとに決めていく、いわゆる“データドリブン”などですね。データはできる限りリアルタイムに分析したいし、さらにはAIなどを活用して、従来の分析では得られないような相関関係や知見も導きたい、となるわけです。
ところが、これまでのやり方だと、必要なデータをそれぞれのシステムから落としてきて、Excelでせっせとまとめる……とかになり、しかも毎回情シスに頼んで必要なデータを出してもらわなきゃいけなかったりします。とにかく時間がかかり、「必要なデータをリアルタイムにパパっと!」とはいきません。
というわけで、バラバラのデータをバラバラに保存しておくだけではなく、データを収集し、フォーマットを整えて、使える形にしたものを一ヶ所にまとめたデータ分析基盤が必要になるのです。
RDBMS・データウェアハウス・データレイクの違いを理解する
では、実際どうやってデータ分析基盤を実現するのか、といったところですが、データ分析基盤に求められるのは、「大容量のデータストアを持っていること」「高い処理性能があること」。そして、専門知識がある人だけでなく、だれでも使える「データ分析の民主化」を実現できる環境であれば理想です。といったところで、まずは代表的な「データを貯めておく場所」についておさらいしておきましょう。
RDBMS
いわゆる“データベース”。テーブル(表)の状態の構造化データを蓄積し、複数テーブル間で連携し、必要な検索(情報の抽出)をすることができます。データの一貫性・信頼性が高いことから、基幹システムなどで採用されていますが、その分、制約も多くなります。「パフォーマンスを上げるためにテーブル設計を変えよう」とか気軽にできません。また、SQLなどの知識が必要で「だれでも使えるよ」とはいかないので、民主的とも言えません。
大容量・高速というところも、お金をかければできないことはないですが、あまり現実的ではないでしょう。
データウェアハウス(DWH)
次はデータ分析基盤ならコレ、というイメージがある“データウェアハウス”です。RDBMSに保存したデータを定期的に収集して一元化したうえで、データ分析基盤をデータベースから独立させられます。つまり、業務アプリケーションと紐づいていたゆえの制約からある程度解放され、設計なども自由度が増します。列志向データベースで、データ同士の相関関係分析に最適された設計になっているので、データベースと比較すると、大規模なデータ分析も高速に実行できます。
ただし、データウェアハウスが扱うのも「構造化データ」なので、動画や音声、テキストなどの「非構造化データ」をそのまま扱うことはできません。これらを分析に使う場合には、必要な形式に変換するなどしたうえで取り込む必要があります。
データレイク
データウェアハウスからさらに一歩進んだものとして、今注目されているのが“データレイク”です。なんといっても、データベース、DWHで扱うことができない非構造化データに対応していることが特長。生のログデータ、ファイル、音声など形式の異なるデータを保存できるリポジトリがあって、直接分析可能。また、大量データを複合的に分析することもでき、機械学習と組み合わせてレポートを生成したり、予測したりといったことも可能になります。
「なんでも放り込んで貯めておける」ことがメリットになる一方で、それをどう管理するのかが問題に。どのデータが、どんな形式で、どこにあるのかをまとめた「データカタログ」をどうやって生成・管理するのかなどを考えなければならず、セキュリティ面も課題です。また、データレイクの場合、一般的に規模が大きくなるため、手動で運用するのが難しく、効率化するソリューションが必要になってくるのも、押さえておきたいところです。
また、クラウドサービスとの親和性が高く、代表的なものとしてAWSのオブジェクトストレージAmazon S3が挙げられます。
一般的なデータ分析のフロー
当然ですが、「データ分析基盤を作ること」が目的ではなく、「データ分析基盤を使ってデータ分析をおこなうこと」、さらに「データ分析の結果をもとに何らかの意思決定をおこなうこと」が目的です。つまり、
- データソースからデータを取り込む
- ストレージに蓄積する
- 使いやすい形に変換&データカタログを作成する
- 分析する
- 見やすくダッシュボードなどで可視化する
……といったフローが必要になります。うえで紹介したDWHやデータレイクは②のデータ蓄積部分にあたりますが、データ分析をスムーズに進めるには、③も結構重要。データレイクだと「とにかくなんでもかんでもデータを貯めておく」ことができますが、もちろんそのままいきなり分析できるとは限らず、必要なデータを紐づけたり、分析しやすい形に変換したりしなければなりません。このプロセスになかなか手間がかかるのも事実。また、データの量や種類もどんどん増えていくなかで、「どこにどんなデータを保管してあるのか」も管理しないと、「欲しいデータがあるのか」「どこにあるのか」が分からず、データがあったのに活用できていない、となんとももったいない状況になりかねません。そのためにも、データカタログを作成して、集めているデータを整理しておく必要があります。
さらにさらに、このフロー全般を通して、セキュリティやモニタリングも必要です。やや気が遠くなりそうですが、各ステップについて、AWSのサービスも用意されているので、それを組み合わせることで実現できます。
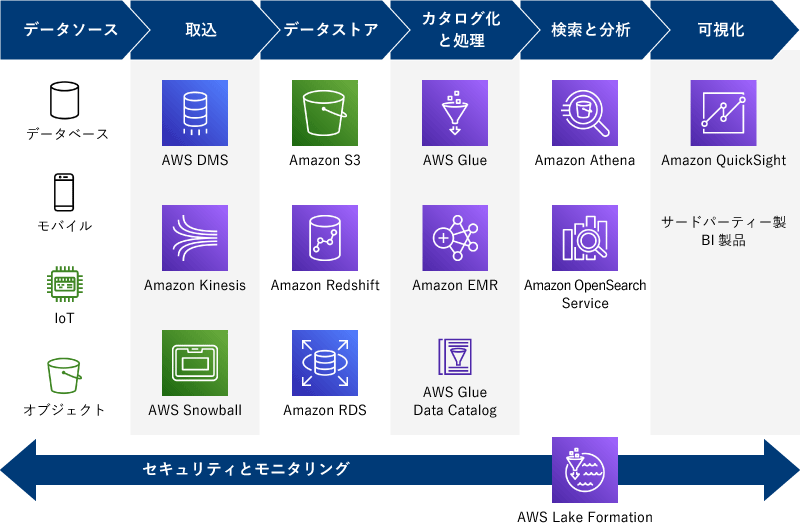
データ分析で利用するAWSサービス
ここでは上記のうち、データ分析基盤として押さえておきたい代表的なものを解説します。
Amazon Kinesis
ストリーミングデータを取り込むためのサービス。IoTやマウスのクリックストリームなど絶えず流れ続けるようなデータをイチイチ蓄積することなく、ストリームの状態のままデータストアまで搬送できるもの。また、ストリームのパイプラインのなかで直接分析・処理することも可能です。
AWS Glue
“ETL”をおこなうサービスで、データを用意する中でも手間のかかるデータ整形の部分を担います。ETLだけでなく、データのクローリングやデータカタログの作成もできて、複数のデータソースからデータを検出して、変換して、統合してという一連の処理を効率化します。
Amazon Redshift
AWSがマネージド型で提供するDWH。列志向型でデータ分析に特化しており、RDBMSに比べて高速な処理・分析が可能です。
Amazon QuickSight
マネージド型サービスが続きますが、今度はBIです。一般的なBIツールと同様に、データをいろいろと分析した結果を可視化するダッシュボードを簡単に作れるシロモノです。
AWS Lake Formation
上の図でも全体にかかる形で配置されていたように、AWS Lake Formationはデータレイク環境全体の構築を効率化するもの。データの取り込みから構築、データカタログ作成、ETLでの変換まで、設定にもとづいて自動に近い形で処理できるようになります。構築したパイプラインが正常に動作しているか、セキュリティに問題ないかをモニタリングすることも可能です。
「大変そう」を解決するためにも、データ分析基盤の構築が必要に
ひととおり、データ分析基盤の概要と、基本的なAWSサービスを解説してきました。いろいろあって大変そうな印象ではありますが、多分、今、現状が「いろんなところにデータがバラバラあって収拾つかないし、まとめて分析するのにイチイチ手間がかかるし、Excelでやるには限界だし、これからもデータは増えそうだし……」とすでに大変なことになっているので、それをどうにか改善するには、やっぱりこういった基盤を整えるのがベストということになるんでしょう。
「はじめようAWS!」シリーズ第19回 ~データ分析基盤(概要編)~

このコラムでは本当に基本の部分のみ解説しましたが、ユースケースごとの構成などまで含めてご紹介しているオンラインセミナーの動画も公開しております。よろしければぜひご覧ください!
Amazon DataZoneリリース、Amazon QuickSight Qの進化……AWS re:Invent 2022で注目したモノ

またこれまでのコラムでも、データ分析基盤や、その先にあるAI・BIについて解説してきました。
昨年末のAWS re:Invent 2022でもこの領域は注目されていて、データカタログサービスがリリースされたほか、BIツールAmazon QuickSightも大きく進化しています。
ゼロETL、Amazon KendraなどAWS re:Invent 2022で見たデータ分析系サービスの進化

そもそも、データ分析系のサービスについてもかなりいろいろ発表があり、手間のかかるETL処理をなくす「ゼロETL」を打ち出したサービスなども登場しました。
ノーコードでAIって本当?Amazon SageMaker Canvasを試してみた

“データ分析”のなかでも、最近どうしたって気になるAIですが、AWSでは専門知識がなくても、ノーコードで使えるツールと謳った「Amazon SageMaker Canvas」が用意されています。というわけで、初心者シイノキが「本当に知識がなくても使えるのか」チャレンジしました。
AWS Innovateレポート!AI/MLプロジェクトが実用化まで進まない理由って?

ついでにAI活用でよく聞かれるのが、「AI/MLはPoC止まり」問題ですが、そろそろ次のステップに行きたい感じもある、はず。
AWS Innovateレポート!Amazon CloudWatch RUM、Amazon KendraなどでECサイトを改善する

AI活用が進んできたとはいえ、やっぱりなんだか「大きな企業がすごいことやってるんでしょ」感は否めず、実際どう使えるのかイメージしにくいもの。そこで、ECサイトを例に、AIを使った課題解決のユースケースを紹介しました。
AWS Innovateレポート!AI/ML活用に欠かせない“データ活用基盤”はどう実現すべき?
そして、今回解説してきたデータ分析基盤の、さらにその先。データ活用するならセキュリティとガバナンス、ちゃんとしておかないとダメだよ、というお話も。
AIが大きなトレンドになり、実用化が近づいてきたんだなと感じていましたが、その次として最近はデータ分析基盤をどう整えるかが大きなトピックになっているように思います。つまり、それだけAIに本格的に取り組む企業が増えて、データ分析基盤が課題になるところが出てきた、ということなんだろうと。この領域は、これからもいろいろとご紹介していく予定です。以上、シイノキでした!