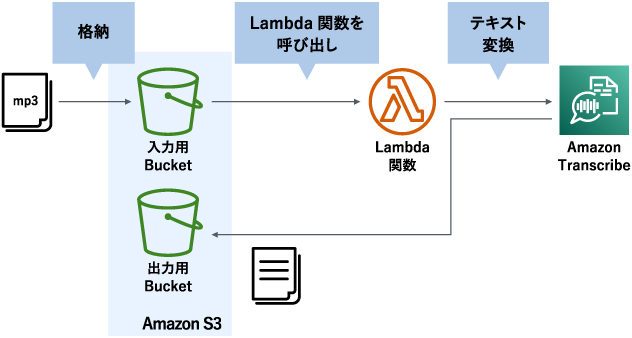
Amazon S3に格納した音声データを自動でテキスト化
まず、今回作成するものの全体像から見てみましょう。メインで使うのはサーバーレスを実現するAWS Lambda(詳細は過去のコラムで解説しています)と、音声をテキストに変換するAmazon Transcribe、そして音声データと文字起こししたテキストデータの保存先として、Amazon S3を利用します。Amazon S3に音声データが格納されたことをトリガーに、AWS LambdaでAmazon Transcribeによるテキスト変換を実行、実行結果をAmazon S3に保存する、という流れになります。
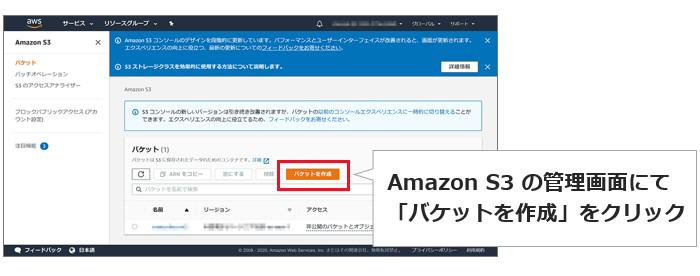
ステップ1:Amazon S3のバケットを作成する
では早速やってみましょう。ざっくりとした手順は下記のとおりです。
- Amazon S3に利用するバケットを作成する
- AWS LambdaでS3バケットにアクセスする関数を作成する
- Amazon Transcribeでテキスト起こしのジョブを作成する
- 「1」のLambda関数から、「3」のジョブを実行する
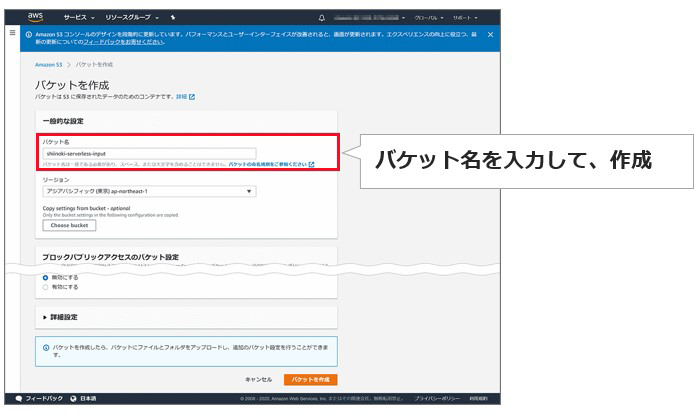
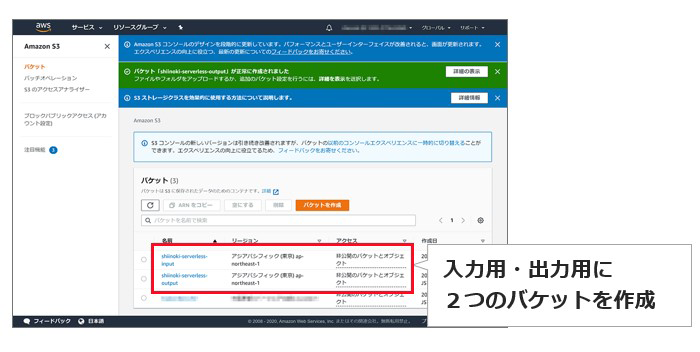
というわけで、最初にAmazon S3でバケットを作成します。ここでは、音声データを格納する入力用Bucketと、テキストデータを格納する出力用Bucketの2種類を作成。マネジメントコンソールでAmazon S3を選択、「バケットを作成」からバケット名のみ入力し(そのほかはデフォルトのまま)作成すればOKです。
手順1
手順2
手順3
ステップ2:AWS LambdaでS3バケットを取得する関数を作る
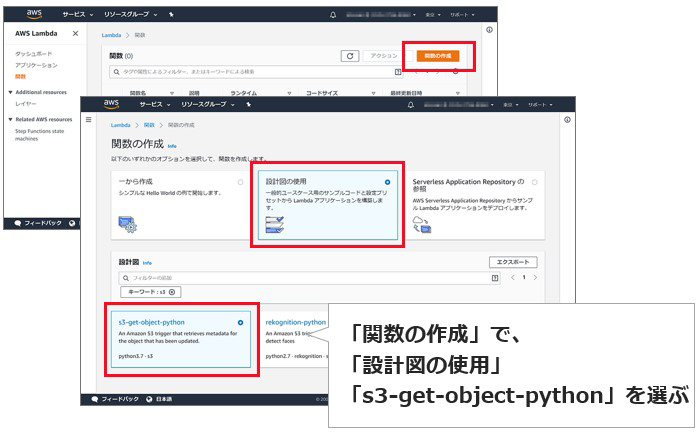
続いて、いよいよAWS Lambdaですが、関数をイチからすべて作成するのではなく、テンプレート的なものを使えばいいようです。AWS Lambdaの管理画面で、「関数の作成」をクリック。「設計図の使用」から「s3-get-object-python」を選びます。「S3からオブジェクトを取得するPythonのソースコード」ということなのでしょうか。割とそのままなので、分かりやすいと言えば、分かりやすいです。
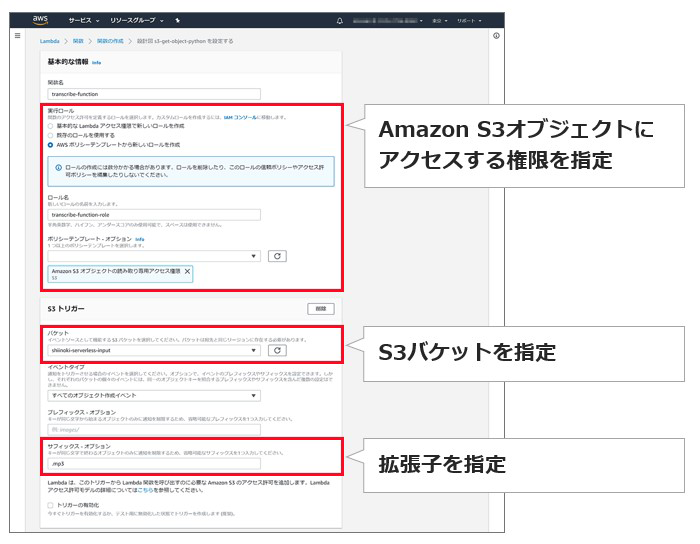
次の画面では、まず「実行ロール」で必要な権限を設定します。今回は「AWSポリシーテンプレートから新しいロールを作成」を使い、「Amazon S3オブジェクトの読み取り専用アクセス権限」を指定しました。さらに、「S3トリガー」として、先ほど作成した入力用のバケット名称と、サフィックスとして「.mp3」の拡張子を指定して完了です!
手順4
手順5
手順6
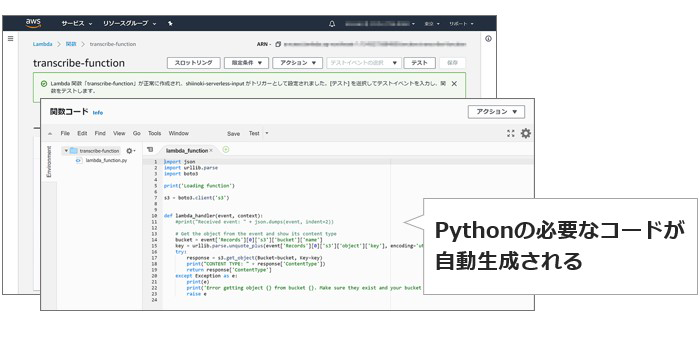
すると……あらかじめコードが生成された状態で、関数ができあがっています!うん!なにをするコードなのかはサッパリ分かりません。古い時代の人なので、Pythonは触ったことがないんだ! どうやら、最初にインポートしている「boto3」というものが、AWSをPythonで操作するためのライブラリとのこと。これを使うことで、S3へのアクセスなどが簡単にできるようになる、というわけですね。
ステップ3:Amazon Transcribeでテキスト起こしジョブを作成する
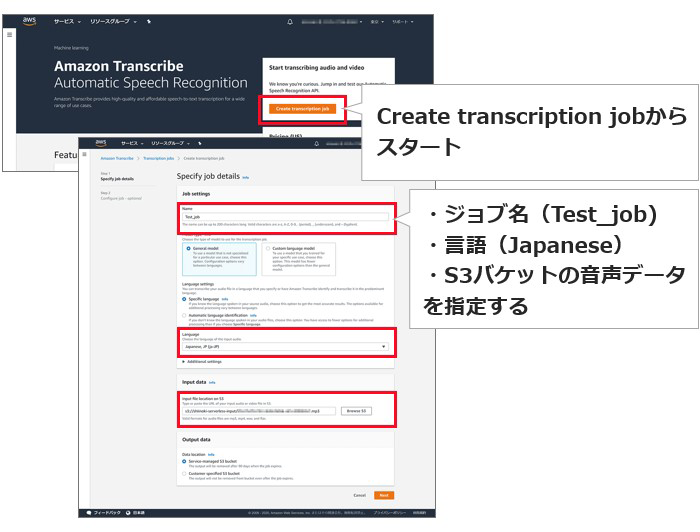
では、いよいよAmazon Transcribeによるテキスト起こしです。いきなりLambda関数から実行するのではなく、まずは単体で使ってみましょう。マネジメントコンソールでAmazon Transcribeを開き、「Create transcription job」をクリック。ジョブ名を適宜入力し、Languageは「Japanese」を選択、Input DataにはS3バケットに格納した、音声データを指定します。オプションはデフォルトのまま「create」を押せばOK!
ステータスが「Complete」になったところで確認すると、確かにテキスト化ができていました。か……簡単すぎる……。
手順7
手順8
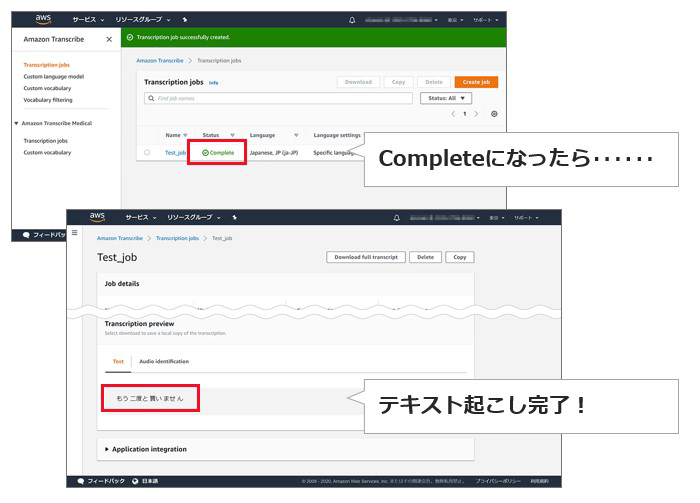
今回は、AWSの音声合成サービスAmazon Pollyで作成した音声をテキスト起こししました。ハンズオンではこの後のステップ(本コラムでは扱いません)でネガティブ判定をするため、「もう二度と買いません」というなかなか不穏なテキストでの実践となっていますが、テキスト起こし自体は完璧にできていることが分かります。
ステップ4:Lambda関数でAmazon Transcribeのジョブを実行する
ここまでで、大体必要な要素がそろってきました。最後に、用意したLambda関数から、Amazon Transcribeのジョブを実行するコードを書けばOKです。
ここでコードを書く前に必要なのが、権限設定です。Lambda関数に必要な権限が設定されておらず、このままではAmazon Transcribeなどを呼ぶことができません。アクセス権限の実行ロールから、「TranscribeFullAccess」と、さらにS3バケットへの書き込みをおこなうため「S3FullAccess」のポリシーをアタッチします。
手順9
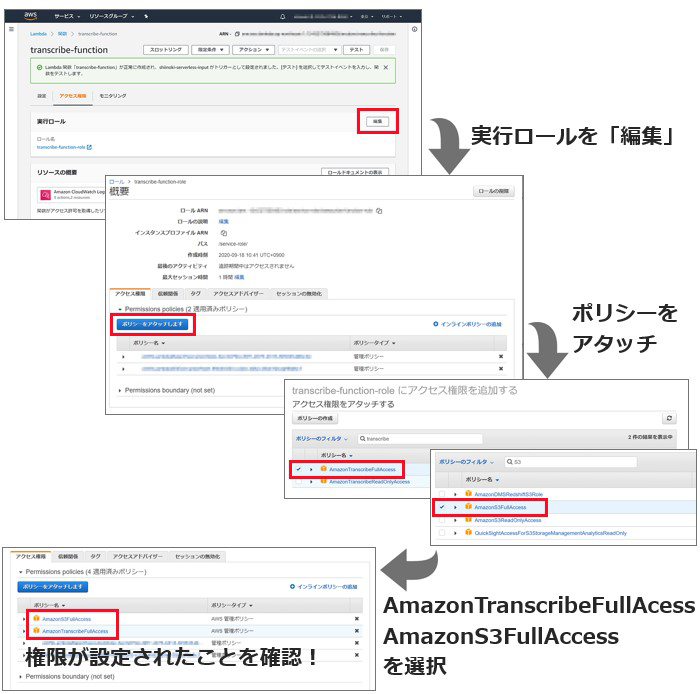
では、実際にLambda関数のコードを修正していきます。ここで参照するのがドキュメント!Boto3のドキュメントが公開されているため、それを見ながら進めます。
今回操作する対象は、Amazon Transcribe、やりたい操作はTranscription jobの実行なので、参照したのはこちら。
ここにはTranscription jobを開始する「start_transcription_job」という関数のサンプルコードが掲載されているので、必要な部分をLambda関数のコード部分にコピペし、変数名やアウトプット先のS3バケット名称を変更して、完成です!
思ったより簡単にできたAWS Lambda、テキスト起こし精度は今後に期待
ではいざ、S3バケットに音声データを再度UPすると……、アウトプット先のバケットにjsonファイルが出力され、しっかりテキスト化された文字列がありました!正直、コードを書く部分は、講師のハンズオンで言われるままやっただけなので、これで次から自分で作れるかというと、まだまだ自信はありません。ただ、ハンズオンではひとつずつ、どこでどう調べればよいのか、なにを調整すればよいのかを説明されていたので、AWS Lambdaをはじめて触るいい機会だったと思います。
このコラムでは音声をテキスト変換するところまでで終わりますが、実際は次のステップとしてこのデータをAmazon DynamoDBに格納し、さらにAmazon Comprehendで感情分析をおこない、ネガティブな内容だった場合はAmazon SNS経由でメール通知するところまで実装しました。これらはAWS Lambdaに加えて、AWS Step Functions workflowを使って各種サービスを組み合わせていきました。このあたりから徐々にひとつずつの手順で「なんのために、なにをしているのか」が分からなくなってきたのですが(言われるがままやってるだけ)、操作自体はそれほど難しくなく、思った以上に簡単なのだな、という印象です。
今回のハンズオンでは、Amazon Pollyで合成した音声をテキスト化したため、かなりきっちりとテキスト変換されていました。当然、音声も明瞭ですし、文章も短く、むしろこれをテキスト化できないなら問題だろう……というレベルです。
気になるのは、これが実際使いものになるのかどうか、です。ということで、手元にあった打ち合わせの音源で試してみたのですが、正直なところ、このままでは厳しいかな、という結果になりました。たまたま複数人が意見を交わすブレストのような打ち合わせだったこともあり、発言が入り混じってしまったほか、当然ではありますが「あー」「えー」といった言葉もすべてテキストになっていて、できあがったテキストをかなり加工しなければ使えない、という状態でした。ただ、Amazon Transcribeは事前によく使う言葉を辞書登録することもできるようですし、特定のひとりが話す講演やセミナーだとまた結果も違ってきそうです。Amazon Connectでの通話内容のテープ起こし用途、と考えると、詳細な会話まで細かく、というと難しいかもしれませんが、ざっくりとした会話の概要やキーワードを把握するためには、十分使えるのではないでしょうか。
人が手作業でテープ起こししたものと同様のレベルがすぐに実現できるかというと難しい気がするのですが、「ちょっと加工すれば使える」ようになるのはそう遠くはないかもしれない、と今後に期待したいと思います。
以上、シイノキでした!
- Amazon Connect 導入支援サービス
-
電話窓口の在宅勤務化を実現する Amazon Connect環境をリーズナブルに 構築できます
- マネージドクラウド with AWS
-
はじめてのAWSから 一歩進んだ活用までトータルサポート
お役立ち資料をダウンロード

「Amazon Connect まとめて解説 入門編」のダウンロードをご希望のお客様は、
以下必要事項をご入力ください。