RAGの仕組み
そもそもRAGはなぜ必要なのかというと、LLMはそのままだと「自社の事情にあわせた回答はしてくれないから」。冒頭でも少し触れましたが、LLMは基本的にインターネットなどにある情報を学習しています。つまり回答で返ってくるのはあくまで一般論。自社の規定や製品のことに特化した回答はしてくれません。前のコラム(生成AIユースケース●効果が出る活用法を考える)でも紹介したとおり、「育児休業はいつまで取得できますか?」という質問があったときに「一般的に1年です」的な回答はいらなくて、「男性は6か月、ただし、主となり育児するケースでは最大1年」のように規定を踏まえて回答してほしいわけです。回答生成時に社内ドキュメントを参照させることで、これを実現するのがRAG、ということですね。
ということで、RAGの仕組みをもう少し深く見てみましょう。ざっくりざっくりまとめると下記のようなイメージです。
RAGの仕組みイメージ
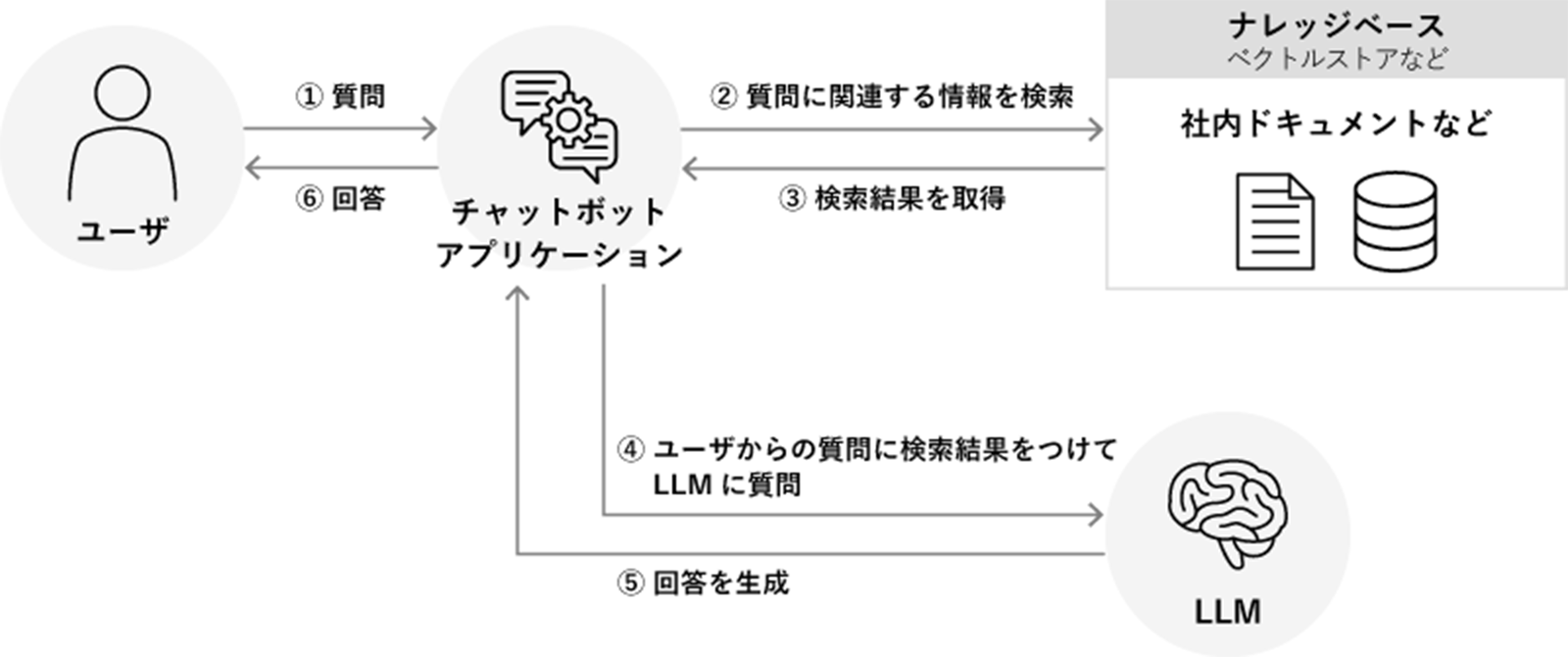
質問(プロンプト)がきたら検索し、結果をもとに生成AIで回答を作成する、という流れですね。冒頭でまとめたものと同じです。で、ここでポイントになるのが、「ナレッジベース」のところに書かれている「ベクトルストア」の存在です。
●ベクトルとはなにか?
「ナレッジベース」とは知識をまとめておく場所のことであり、RAGではベクトルストアを使う、ということになるようなのですが、ベクトル……あー……多分きっと高校時代に数学とかで出てたりしたやつですよ…ね……?まったくさっぱり記憶がないので、気を取り直して、AWS Summit Tokyo 2024のセッションで聞いた話をまとめましょう。
文章や画像などを“検索”する場合、人が調べるときは「どれが似ているか(関連しているか)」をなんとなく感覚で判断しますよね。同じ動物が写っているとか、文章でも「同じテーマについて書いてある」とか「調べている規定の情報が書いてありそうか」とかとか。ただ、その“感覚”、データの世界ではそのままでは再現できません。ベクトルはつまり、このような「そのままでは似ているものを検索できないデータ」を検索できるようにするための方法なのだと。「ベクトルに変換する」とは、とてもとても大雑把に言うと「文字や画像を数字列に変換する」ということで、「変換した値が近ければ同じような意味を持つ」ということになります。
ベクトル化した数値をもとにマッピングしたイメージ
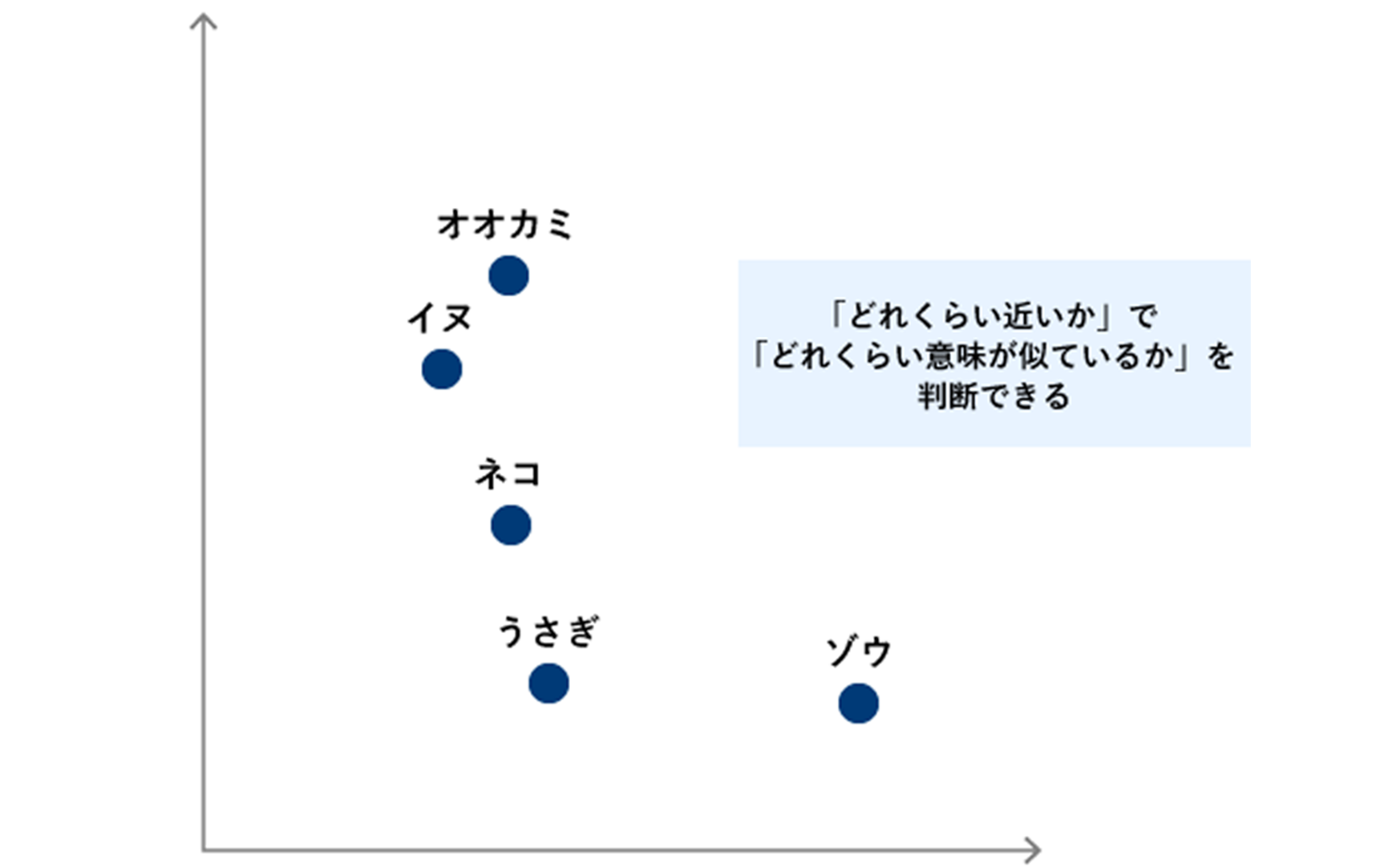
そして、このベクトルに変換する作業のことをEmbeddingと呼びます。ほぉう?技術的には想像がつきませんが、たとえばAWSが提供する生成AIのモデル「Amazon Titan」はEmbeddingにも対応しているので、細かな仕組みがさっぱりわからないままでもきっと大丈夫。
ちなみに、ベクトル化したデータを貯めておく場所がベクトルストアであり、AWSでもAmazon OpenSearchやAmazon Auroraなどいろいろと用意されています。
構築後、「データをきちんと更新すること」を忘れずに
さて、「比較的簡単に構築できるよ」とされているRAGですが、これも1度構築すれば万事OK♪とはいきません。質問のたびに、ドキュメントを参照して回答を生成するわけですから、参照先のドキュメントが古ければ、回答も古くなってしまいます。つまり、参照するドキュメント=ベクトルストアが、定期的に最新のデータに更新されていることが重要、ということ。というわけで、データベースなのか、ファイルサーバなのか、S3バケットなのか、とにかく元となるデータソースから定期的にデータを取り込む必要があります。データを取り込む頻度は、用途やデータの内容にあわせて決めればよく、ストリーミングでリアルタイムに取り込むこともできれば、週1回バッチ処理で取り込むこともできます。更新頻度が低いドキュメントであれば、手作業で更新するのもアリでしょう。RAGを実装するときに、「どうやってデータを更新するのか」もあわせて検討しておくことがポイントです。
AWSなら、RAGの実装も簡単に
RAGの仕組み自体はあくまで一般的なものですが、AWSにはRAGに必要なサービスがすでにいろいろとそろっています。これまでこのコラムでも何度も取り上げている生成AIサービス「Amazon Bedrock」はその筆頭ですが、2023年12月には「Knowledge Bases for Amazon Bedrock」がリリースされ、RAGで必要な処理・仕組みを簡単に実装できるようになりました。もちろんデータ格納先としてのDBもいろいろありますし、Amazon S3に保存したデータも活用できます。
さらに、活用を進めていくと気になる生成AIの監査やセキュリティ対策もカバー。たとえば、「Guardrails for Amazon Bedrock」では生成AI(Amazon Bedrock)を使うときに自社のポリシーに則っているかどうかを監視することができます。ほかにも、ログの取得や監視には、AWS CloudTrailやAmazon CloudWatchを使えるので、AWSに構築したほかの環境とあわせて管理できるのも魅力でしょう。
ソニービズネットワークスではRAGを用いた社内FAQボットの構築サービスをリリース。まずは生成AI活用をはじめてみよう!という際に、手軽にスタートできるメニューとなっております。気になる方はぜひお問い合わせください。
次回は、生成AI活用とあわせて考えておきたい、セキュリティやリスクの話についてご紹介したいと思います。以上、シイノキでした!