データ分析の課題と、データ分析基盤の要件
はじめて「データドリブン」という言葉を聞いたのは何年前だったか、今はもうその重要性に異論がある人は少ないでしょう。ところが「99%の企業が目指しているのに、成功している企業は26.5%に留まる」という調査結果もあるのだとか。なぜそこまでうまくいかないのでしょうか?
企業が抱える課題として、「①データがサイロ化している」「②ビジネス変化に対応できない」「③パフォーマンスの問題」の3つが挙げられていました。データのサイロ化はどこでもよく言われることですが、②③はHadoop(※)などを構築し、データを集約している企業に多く見られるのだそう。そこまでデータ基盤を作ったなら、活用が進んでいそうなものなのに、うまくいかないとはハードモードすぎる気がしますが、オンプレミスでこういった環境を構築していると、AIや機械学習の実用化が進んで、新しい手法で分析したいなど、データ活用のニーズが増えても、うまく対応できないのだとか。パフォーマンスについても、オンプレミスではサッと増強とはいきません。
こういった課題を解決する「データ分析基盤」としては、ユーザのニーズに柔軟かつ迅速に対応できること、運用コストを最小限に抑えられることが必須要件に。また、ほしいデータをその都度管理者に依頼しなければならないのでは大変なので、使いたいタイミングで使いたいデータを使える「セルフサービス」がキーワードになります。最後に、データ量も分析内容も変化するなかで、ワークロード側がよしなに対応してくれる「自動スケーリング」も重要と言えます。
……要するに、こういった要件をクリアした環境を実現するのに、多くの企業でAWSのサービスがいろいろと使われていますよ、という話、でした。
- ※ Hadoop:大規模データの分散処理をおこなうミドルウェア
データ準備・前処理は「逆から考える」ことが重要?!
さて、ここからが本題です。データ分析基盤では、基幹システムなどからデータを集めて、ストレージに格納し、加工したりノイズを排除したりして分析しやすいデータを用意。そこまできたデータをBIツールや機械学習で分析することになります。どうしてもBIツールや機械学習が注目されがちですが、思った以上に大変なのが、「データを収集してストレージに格納して、使いやすいように整形する」までのところです。
ここでポイントになるのが、「得たいリターンから、データを逆算すること」なのだそう。普通に考えると「こういうデータがあるから、これを連携して、なにができるのか」となりそうですが、そうではなく、「こういう分析をしたい。そのためになんのデータが必要か」から考えるのだと。こうすれば、「一生懸命集めたデータが使われない」こともなくなるし、「データは集めたけれど、それで何をするか“アクション”が決まらない」なんてこともありません。厄介なデータ収集から格納、加工までの調査・調整も最小限にできるというワケです。なるほど。
データ連携方法を考えるときの3つのポイント
取り込みたいデータが決まったら、次はどう連携するのか「連携方法」を考えることになります。ここでポイントになるのはデータソース・格納先・必要なデータの鮮度、の3つです。
データソースはデータベースやファイルのほか、SaaSアプリケーション、ストリーミングデータ、さらには天候情報や株価情報などサードパーティーデータまで、どこからデータを持ってくるのかです。格納先もいろいろですが、主にAmazon S3かAmazon Redshiftのどちらかになるでしょう。両方を組み合わせて使うこともあります。
そしてデータの鮮度は、1日前のデータがあればいいのか、直近数時間のデータがほしいのか、可能な限り最新のデータがないと困るのか……といったところです。1日前のデータがあればいいのに、リアルタイムに収集しても意味がないですし、逆もまた困りもの。用途によって必要な鮮度は確認しておきましょう。つまり、これを決めるためにも先に「どう使うのか、どこでどう分析するのか」を決めておくことが大事、となります。話がしっかりつながりますねー。
では、いよいよいくつかの組み合わせについてデータ連携パターンを解説しましょう。
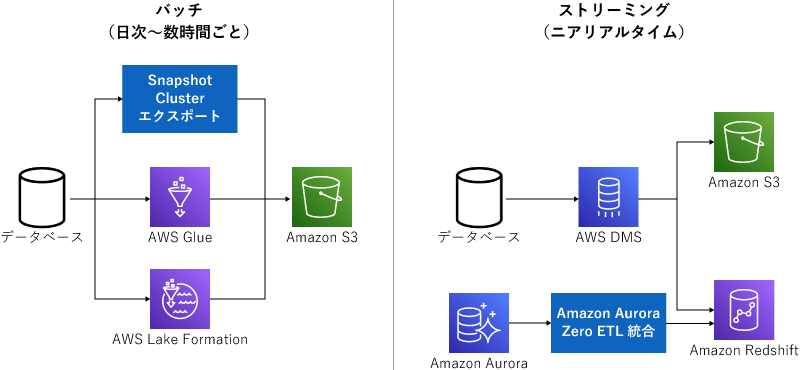
データ連携パターン①:データベースからAmazon S3に
まずは王道、データベースからAmazon S3にデータを連携するパターンです。これはやり方が大きく2種類あり、日次や数時間単位で連携すればOKならバッチ処理、リアルタイム連携ならストリーミング処理です。たいていはバッチ処理で足りるはずですが、たとえば「サブスクリプションが解約された」みたいなビジネス上のクリティカルなイベントをすぐに顧客チームに連携したい!という場合などで、ストリーミングを使うのだそう。そこまでシビアなケースは珍しそうですね。
バッチ処理の場合も、Amazon AuroraやAmazon RDSのデータをエクスポートしたり、AWS Glueで抽出変換したりといくつかのやり方があります。AWS Lake Formationを使ってデータ連携のパイプラインを作ることも。データ収集のテンプレート「Blueprints」も用意されているので、それを使うのもアリです。
ストリーミングの場合は、AWS DMSを使います。データベースの移行時に使うサービスですが、これを使ってリアルタイムに連携できるのだそう。Amazon S3に連携するときには、更新履歴が積み上げられていくので、最新の情報だけを見たいというときには、ETLなどで更新履歴をマージしなければならないので注意が必要です。あとは、AWS re:Invent 2022で発表されたAmazon Aurora Zero ETL integration with Amazon Redshiftもリアルタイムでデータ連携できるもの。限定プレビューで使えるので、これも今後有力な候補になってくるでしょう。
データ連携パターン:データベース
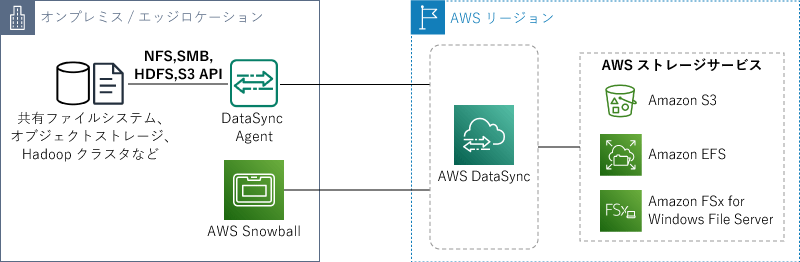
データ連携パターン②:ファイルの連携(ファイルサーバ)
オンプレミスのファイルサーバから、AWSにファイルを連携したい、その場合は「AWS DataSync」を使います。これはオンプレミスやほかのパブリッククラウドサービスとAWSのストレージを連携するサービスで、スクリプト不要、設定だけでファイル連携を実現できます。ちなみに、とにかくデータが大量とか、ネットワークを経由するのが難しいときには、AWS Snowballと組み合わせて連携することもできます。
連携先はAmazon S3のほか、Amazon FSx for Windows File Serverなども選べます。
データ連携パターン:ファイル(ファイルサーバ)
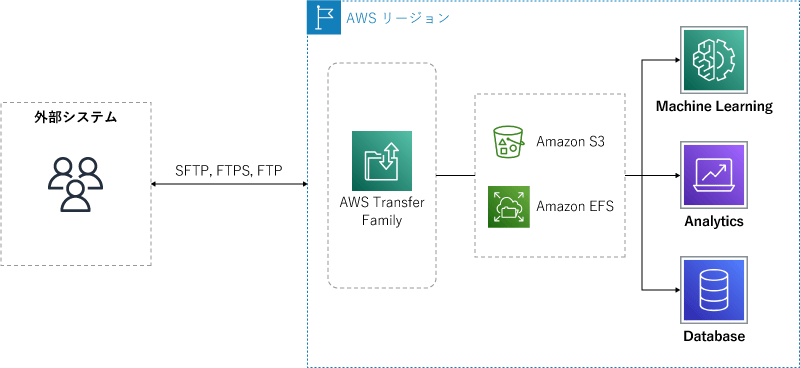
データ連携パターン③:ファイルの連携(外部システム連携)
もうひとつファイルの連携ですが、FTPやSFTPで外部システムと連携するパターンです。ここでは、FTPを用いてストレージと連携する「AWS Transfer Family」を利用します。
Amazon S3などにファイルを格納したあとは、ワークフローを作って転送したファイルに対して自動で処理をおこなうことも可能。たとえば、暗号化されていたファイルを復号したり、なにかを通知したり、データ分析の下処理をして、分析ツールに連携したりもOK。ここまで簡単に構築できるのはなかなかすごいですね。
データ連携パターン:ファイル(外部システム連携)
データ連携パターン④:SaaSアプリケーション
続いては、SaaSのデータを連携したい、というニーズです。マーケティングとかCRMとかSFAとか、いろいろ使っている企業も多いんじゃないでしょうか。そこで登場するのが「Amazon AppFlow」。さまざまなクラウドサービスとAmazon S3/Amazon Redshiftを数クリックで連携できるというもの。Salesforce、Google Analytics、Service Nowなどかなりいろいろなサービスとネイティブに連携できるうえ、AWS側からクラウドサービス側にデータを送信することもできちゃいます。もちろんGUI操作のみ、ノンコーディング。たとえば、Marketo(マーケティングオートメーション)で獲得した新しい顧客データを、Salesforceに入れる、とかも自動でできちゃう。なにそれすごい。
SalesforceからAmazon S3にデータ連携するデモがありましたが、「どのデータを持ってくるのか」などをポチポチと選ぶだけで進んでいき、本当に簡単に連携できていました。「オープンになっている商談だけ」など簡単なデータクレンジングもできるそうで、さらに持ってきたデータをAmazon Athenaに連携すればSQLで検索できるようになるし、Amazon QuickSightで可視化したり、Amazon SageMakerで機械学習したり……とかなり活用の幅が広がります。
データ連携パターン⑤:ストリーミング
ストリーミングデータと言えば、「Amazon Kinesis」です。ストリーミングデータは、IoTセンサーのデータやモバイルアプリケーションのログなど常に流れ続けるようなデータですよね。
そして、Amazon Kinesisのサービスのなかでも「Amazon Kinesis Data Firehouse」というのがありまして、ストリーミングデータをAmazon S3に蓄積するところまでノンコーディングで実現できるスグレモノ。これを使うことで、たとえば、モバイルアプリケーションのログを解析し、お客さんの関心がなくならないうちに、リアルタイムでクーポンを配信する、なんてことができてしまう。ダメじゃん!ECサイト見ながらまんまと買っちゃうヤツじゃん!すごい世界がやってきたものです。
データ連携パターン⑥:サードパーティーデータ
主に機械学習で、天気や株価などサードパーティが公開しているデータを自社のデータに組み合わせて分析したいというニーズが増えています。とはいえ、データの公開元を調べて契約する必要があり、複数のデータが必要なら当然それぞれやらなければならない。え、面倒……となりますよね。
そこで便利なのが、「AWS Data Exchange」。認定データプロバイダが提供するデータを簡単に検索できて、サブスクライブするだけで直接Amazon S3やAmazon Redshiftに保存できるというモノです。
いわば、データのMarketplaceということでしょうか。こんなところまでサービスがそろっているのはさすがと言うしかありません。
データ連携の解決策はそろっている!
データ活用・AI/MLが注目されるなか、「実は大変なのは、その前のデータを用意するところ」という話をよく聞くようになってきました。現状や課題を聞けば聞くほど厄介そうで、これ、どうにもならなくない?みたいな気持ちになったものですが、その解決策はすでにそれなりにそろっているのだなと感じました。今回は今まで知らなったサービスも多く登場していて、しかもノンコーディングでポチポチと使えるものも少なくありません。「サービスはそろっているけれど、使いこなすにはスキルが必要」だったAWSではもはやなくて、「必要なものは全部簡単に使えるようにそろえておいたから」というところまできていると印象付けられるセッションでした。次回は、Amazon QuickSightのセッションを取り上げたいと思います。
以上、シイノキでした!