コンテキストエンジニアリングとは?
LLM に対して、タスク実行に必要な情報を上手く引き渡す技術の総称です。
従来のプロンプトエンジニアリングとの違いは、LLM に対して与える1回の指示を対象とするのに対して、コンテキストエンジニアリングは、プロジェクトの README.md や AmazonQ.md、関連ライブラリ情報等、与える情報全てを含む点にあります。
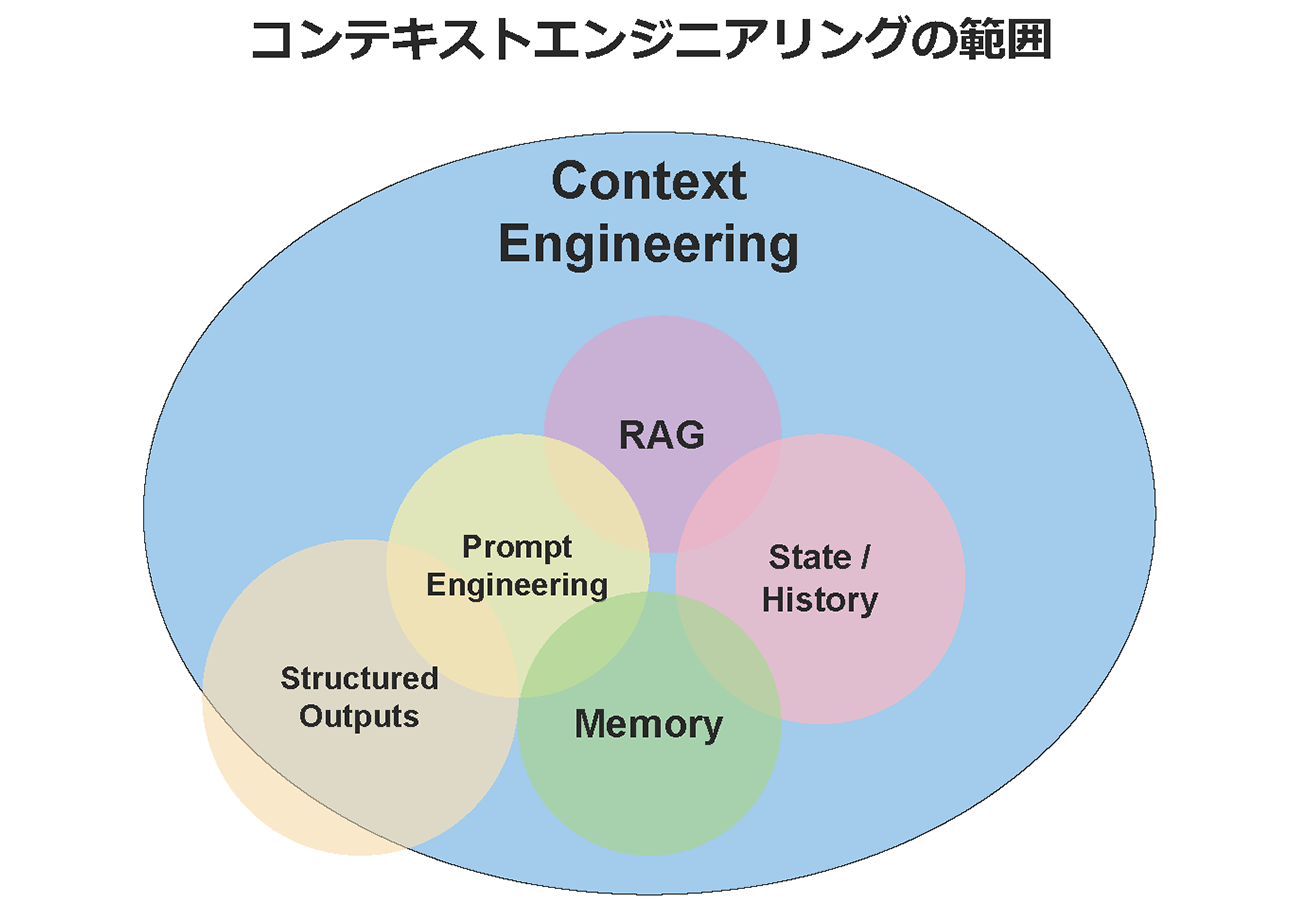
広義では、コンテキストエンジニアリングは LLM の精度を上げる為の RAG や Memory、会話履歴も包含します。
なぜコンテキストエンジニアリングが重要なのか?
結論から言うと、LLM のコンテキストサイズには限界があるから、です。
LLM の精度を上げるには、必要な情報だけを上手く伝える必要があります。
なぜこんな仕様になっているのか、2つの理由があります。
コンテキストエンジニアリングが重要な理由: 1. AI エージェントの記憶力には限界がある
コンテキストとは、狭義では人間と LLM の間でやり取りされるデータを指します。
Strands Agents フレームワークのサンプルコードを元に解説します。
python
from strands import Agent
# エージェントを初期化
prompt = "今日の世界のニュースを調べて下さい。"
agent = Agent(
system_prompt=(
"あなたは人間を助ける AI アシスタントです。"
"情報収集とパーソナライズされたアドバイスを提供するためにツールを使用してください。"
"常に根拠を説明し、可能な限り情報源を引用してください。"
)
messages=[
{"role": "user", "content": [{"text": "おはようございます!あなたの名前を教えて下さい。"}]},
{"role": "assistant", "content": [{"text": "おはようございます!私の名前は Claude です。"}]}
])
# 会話の実施
agent(prompt)
このエージェントには現在、プロンプト(prompt 変数)として “今日の世界のニュースを調べて下さい。” が与えられています。
この時、エージェントは prompt の中身のみを考慮するのではなく、事前に与えられている system_prompt と、messages の中の会話履歴を踏まえて回答します。
毎回のやり取りを messages に追加して、prompt で新しい命令を与えるから、エージェントは過去の会話を記憶して対応出来るのです。
しかし、無限に会話を続けられるかというと、そうではありません。
各 LLM では、一度にやり取りできるコンテキストサイズの上限が決まっています。
現在(2025/07)メジャーなモデルの最大入力トークン数比較
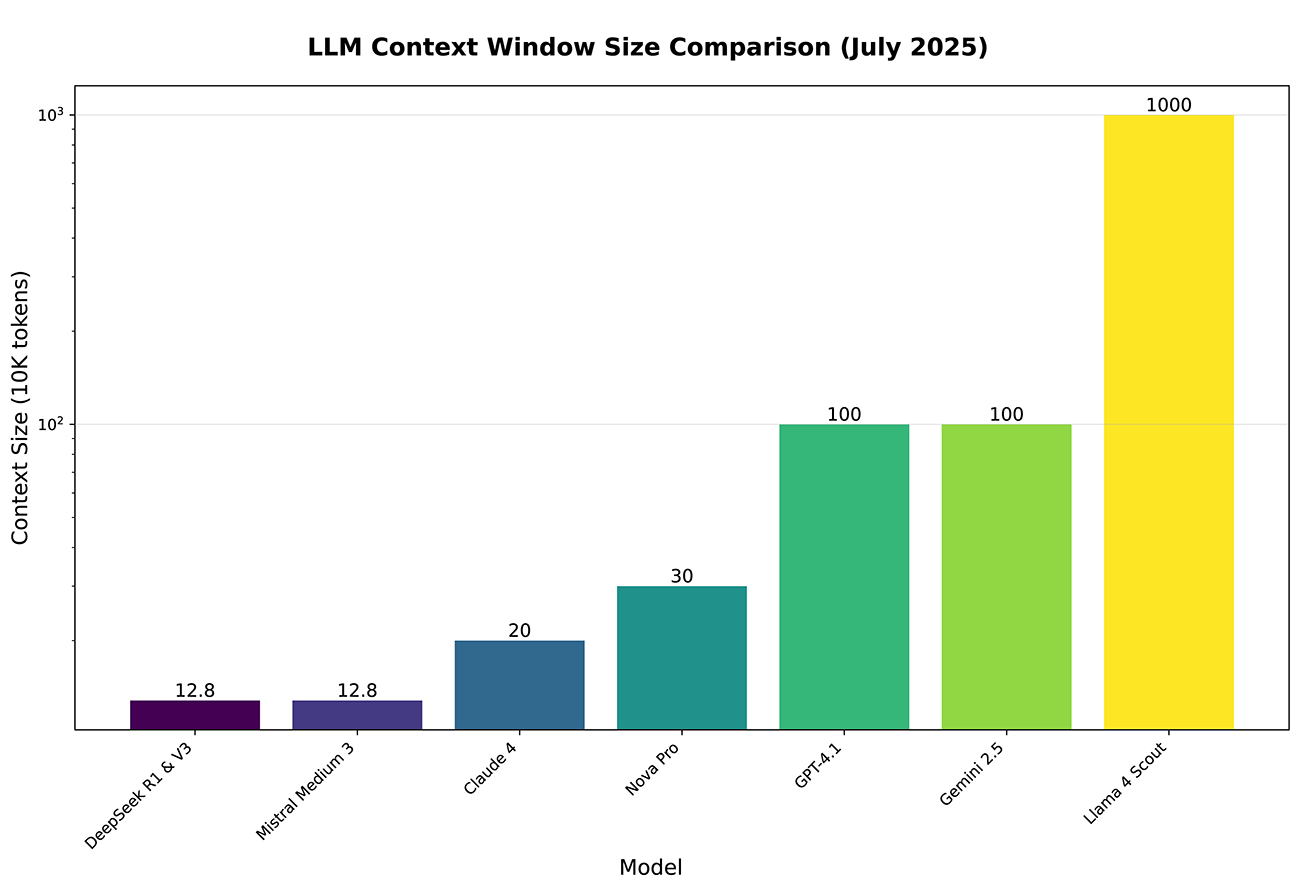
つまり、Claude 4 を使ってエージェントを実行する際、会話の履歴や背景情報など全てを20万トークンに収めなければならない、という事です(Llama 4 Scout の 1000万トークンには夢がありますね)。
コンテキストサイズの上限が、そのままエージェントの記憶力の上限になります。
コンテキストエンジニアリングが重要な理由: 2. "Lost in the Middle"現象
では、20万トークンギリギリまでデータを詰め込めば精度が上がるのかというと、実はそうではありません。コンテキストサイズが大きくなるにつれて、”Lost in the Middle”と呼ばれる現象が発生しやすくなります。
“Lost in the Middle”現象は、コンテキストに含まれるトークンが増えすぎると LLM の精度が落ちる現象です。
2023年に論文で発表され話題となりました。
この論文では、言語モデルはコンテキストの中間部分に配置された情報を効果的に利用できず、コンテキストの始めと終わりに配置された情報をより優先する傾向がある、と述べられています。
もちろん本論文には、「位置バイアスを考慮した設計を行う事で回避出来る」「適切に学習させたトランスフォーマーモデルを使う」「タスクの性質によってモデルの理解力が変わる」等、様々な反論があります。
しかし、LLM の精度を上げるには様々な工夫が必要という、この考え方こそがコンテキストエンジニアリングです。
このように、エージェントの性能を上げるには、与えるコンテキスト自体の設計が非常に重要になります。
コンテキストエンジニアリングの手法
では、コンテキストの質を高めるにはどうすればいいのか。
現在主流になっている4つの手法をご紹介します。
Write Context
「Write Context=コンテキストを書く」とは、エージェントが自ら情報を記録・保存できるようにする手法です。
人間が仕事中にメモを取るように、エージェントが重要な情報を記録し、後で参照できるようにします。
主な実装方法は以下の2つです:
1. スクラッチパッド (Scratchpads)
コンテキストウィンドウの外部に情報を保存するメカニズムです:
- ファイルへの書き込みツール:エージェントがメモや中間結果をファイルに保存
- 状態オブジェクトのフィールド:ランタイム中に情報を格納
メジャーな例だと、Claude や Strands Agents の「think」ツールのように、プロセスの外側で考える時間を提供するものがこれにあたります。
2. メモリー (Memories)
複数のセッションにわたって情報を永続化する仕組みです:
- リフレクション型:各ターンの後にエージェントが学んだことを振り返り記録
- 定期的な統合:一定期間ごとに情報を統合して長期記憶として保存
例えば、ユーザーの好みや設定を記憶してパーソナライズしたり、プロジェクト固有の知識を蓄積して精度を上げたり、が可能になります。
これらの手法により、エージェントは単なる一問一答の処理を超えて、文脈を理解し、継続的に改善される知的なアシスタントとして機能できるようになります。
Select Context
「Select Context=コンテキストを選ぶ」とは、膨大な情報の中から、実行するタスクに最も関連性の高いコンテキストを選択的に提供する手法です。
全ての情報を渡すのではなく、必要な情報だけを賢く選ぶことで、精度向上とコンテキストサイズの最適化を両立します。
例えば、エージェント自身が前述のスクラッチパッドやメモリーから適切な情報を選んだり、タスク解決に最適な ツール・MCP を選択できるようにすると、必要なコンテキストだけを取得出来るようになります。
現在メジャーな情報選択のための技術としては RAG やナレッジグラフ、リランク等が使われています。
Compress Context
「1. AI エージェントの記憶力には限界がある」での解説の通り、エージェントは作業・会話の内容を messages の配列に格納していきます。
当然何もせずに放置すると、作業が進むにつれてこの配列が肥大化して行き、コンテキストサイズの上限に引っかかってしまいます。
ですので、適切なタイミングで古いコンテキストを「圧縮」してあげる事が重要です。
コンテキストの圧縮には主に2つの手法があります:
1. コンテキストの要約 (Context Summarization)
長い会話や作業履歴を要約して保存する方法です。例えば、Claude Code はコンテキストウィンドウの95%に到達すると自動的に「auto-compact」機能が発動し、過去の会話を要約します。
2. コンテキストのトリミング (Context Trimming)
不要な情報をフィルタリングまたは削除する方法です。例えば、Strands Agents は古いメッセージから順に削除する「スライディングウィンドウ」や、古い会話を要約して圧縮する機能(前項の圧縮と同じ)を持っています。
これらの手法を組み合わせることで、コンテキストサイズを管理しながら、重要な情報を保持し続けることが可能になります。
Isolate Context
「Isolate Context=コンテキストを分離する」とは、タスクごとにコンテキストを分けて管理し、必要な情報だけを適切なスコープで扱う手法です。
これにより、コンテキストの混在を防ぎ、各タスクに最適化された環境で処理を実行できます。
主な手法は以下の2つです:
1. マルチエージェント戦略
複数のエージェントに専門的な役割を持たせて、コンテキストを分散させる方法です。
例えば Web 開発プロジェクトでは、以下のようにエージェントを分散させる事で、それぞれのタスクに集中させる事が出来ます。
- フロントエンドエージェント: React/CSS のコンテキストのみ
- バックエンドエージェント: API/データベースのコンテキストのみ
- テストエージェント: テストフレームワークのコンテキストのみ
2. 環境によるコンテキスト分離
サンドボックスを使用してコンテキストを LLM から分離する方法です。
タスク内で計算処理が必要になった場合、python ファイルを生成して、分離された環境でコードを実行、結果を取得する事で、コンテキストサイズを節約する事が出来ます。
これらの手法により、大規模なプロジェクトでも効率的にコンテキストを管理し、エージェントの性能を最大化することができます。
まとめ: LLM の精度を上げるにはコンテキストの使い方が重要
以上が、現在主流となっているコンテキストエンジニアリングの手法です。
Claude Code や Amazon Q Developer を使っている方なら何となく見た事があったのではないでしょうか。
コンテキストサイズが大きいからと言って何でも突っ込めばよいという訳ではなく、様々な手法を使って、適切に取捨選択する事が重要です。
注意事項として、コンテキストエンジニアリングはまだまだ登場したばかり(2025年7月現在)の領域です。
今後も様々な手法が登場して、ベストプラクティスも変わっていくと思われます。
その時点での最新情報を取り入れながら、コンテキストエンジニアリングを実践していく事が重要です。
今回の知識を活かして、ぜひ Amazon Q Developer を使いこなして下さい!
以上、AWS Ambassador の濱田がお送りました。
参考文献
- Context Engineering: https://blog.langchain.com/context-engineering-for-agents/
- Lost in the Middle: How Language Models Use Long Contexts: https://aclanthology.org/2024.tacl-1.9/