生成AI、精度を高める4つのアプローチ
生成AIでどう効果を出すかを考えるということは、つまり基盤モデルをどう活用するか、どこまでカスタマイズするか、とも言えます。そもそも基盤モデルとは、ものすごく簡単にまとめると事前に大量のデータを学習させたモデルのことで、生成AIの中核となる技術です。これによりさまざまなユースケースに対応できるのが特長で、テキスト生成や要約、情報の抽出、翻訳、画像生成といろいろできるのですが、“企業ごとの用途やビジネスにあわせたデータ”を学習しているわけではありません(当然)。なので、期待する回答が得られないこともあるし、そのままだと業務では使えない、というケースも多いはず。といったところで、汎用的な生成AIをそのまま使うだけでなく、いろいろなアプローチで精度を上げていきましょう、ということです。そして、代表的な手法として挙げられるのが、下記の4つ。
- プロンプトエンジニアリング
- RAG
- ファインチューニング
- 継続的事前学習
ちなみに、上から順にハードルが低く、下にいくほど複雑でコストもかかります。そしてさらにこの先には基盤モデル自体を独自に開発しちゃうぜ!という方法もあるのですが、それはあまりにアレなので、置いておいて。この4つについて、詳しく見ていきましょう。
<パターン1>プロンプトエンジニアリング
まずは1番身近な方法から。生成AIの使い方として、「こう質問すると、いい感じの回答がもらえるよ」というハック的なモノ、多く出ていますよね。それです。
生成AIは質問の仕方次第で回答の精度が変わってくるので、ここをうまく利用しよう、という方法ですが、生成AIへの質問を変えるだけなので、取り入れるハードルはかなり低い。「背景となる情報を含める」「なるべく明確かつ簡潔に指示する」「回答例を提示する」「複雑なタスクは分割する」などやり方はいろいろあります。たとえば、「この文章を要約してください」とだけ依頼するよりも、「この文章の概要をブログに投稿できるよう要約してください」と「ブログに投稿したい」という背景情報をあわせて入力した方が期待するものが出てくる可能性が上がる、というイメージです。社内の業務やタスクごとに、プロンプトのテンプレートなどを作って共有しておくのもアリかもですよね。このあたり、ソニービズネットワークスのエンジニアであり、AWS Ambassadorの濱田さんがブログ「Amazon Bedrock入門: Claude におけるプロンプトエンジニアリング基礎」で解説しているので、ぜひそちらもチェックしてみてください!
まずは、「基盤モデルには手を入れず、質問の工夫で精度を上げよう」という1番ハードルの低い方法でした。
<パターン2>RAG
続いてはRAG(Retrieval-Augmented Generation、検索拡張生成)と呼ばれる方法です。これは、質問に対していきなり生成AIで回答を作成するのではなく、まず該当する内容が書いてあるコンテンツを探して、それをもとに生成AIに回答させる、というもの。こちらも基盤モデル自体に手を入れるわけではありません。
RAGの利用イメージ
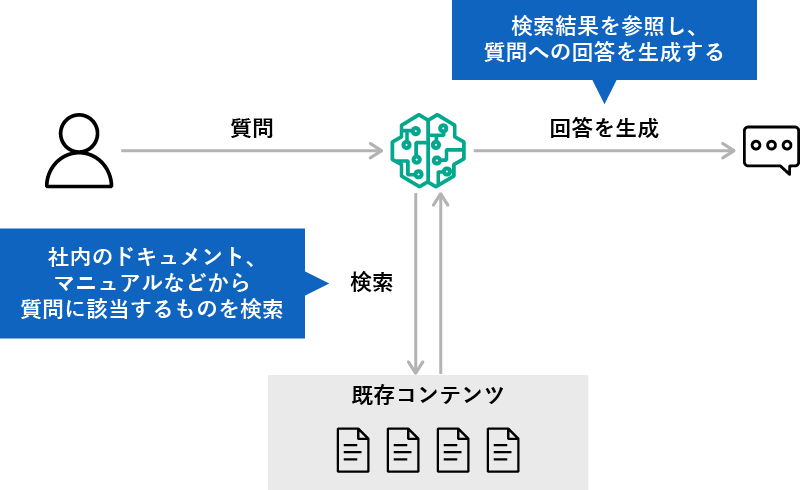
最近では、チャットボットなどで多く用いられていて、たとえば社内規定とか自社製品・競合などの情報、製品マニュアルなどを参照させることで、自社の状況を踏まえた回答をさせることができます。
プロンプトエンジニアリングと比べると、RAGの環境を実装する必要はあるものの、AWSだとこのあたりに必要なサービスもひと通り揃っているので、比較的スムーズに環境を用意できますよ、基盤モデルに手を入れない分、ハードルが低いですよ、といった感じになります。
<パターン3>ファインチューニング
さて、いよいよ基盤モデル自体をカスタマイズするところに入っていきます。ファインチューニングというのは、ラベルありデータを用いて基盤モデルを再学習させ、自社の用途にあわせてチューニングする、というものです。
……はて?どういうことでしょう?という感じなので、ここではひとつ例をベースに解説したいと思います。
ヘルプデスクでオペレータとお客さまの会話を、生成AIに要約させたい、と考えたとしましょう。会話をテキスト化して生成AIに投げて要約させ、うまく精度が出ればそれでOKですが、商材が専門的なものだったりするとそのままでは期待するレベルに届かないことがあります。そこで、「会話をテキスト化したデータ」と「それを要約したデータ」を別途用意し、正解データ(ラベルありデータ)として生成AIに学習させるんです。この「要約したデータ」は「こうやって要約してほしいんだよ」と期待しているものを人が用意します。もちろん生成AIで要約したものを人が調整してもいいですし、これまでオペレータさんが通話後に入力していた記録などを使うのもアリでしょう。このデータを追加で学習させておくことで、生成AIの要約精度を上げられるよ、ということですね。
ファインチューニングの利用イメージ
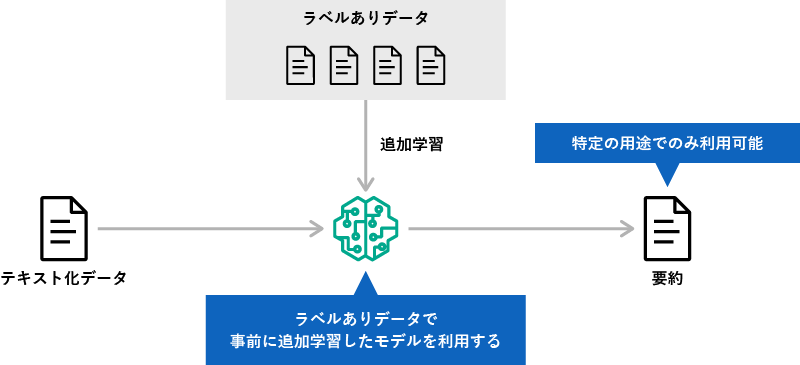
この方法のポイントは、「ラベルありデータで学習させること」と「特定の用途にあわせてチューニングすること」の2つ。ラベルありデータの用意など手間がかかりますが、自社の特定の用途にフィットした生成AIになる、というイメージです。
<パターン4>継続的事前学習
じゃあ、さらに次のステップになる継続的事前学習ではいったいなにをするんでしょうか。ファインチューニングが特定の用途にあわせてチューニングしたのに対して、継続的事前学習ではより広範な用途に使えるように、ラベルなしデータを用いて学習をおこないます。
継続的事前学習の利用イメージ
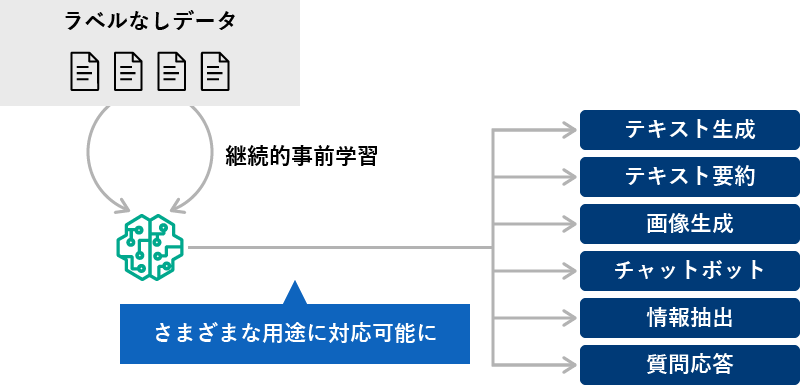
たとえば、業務効率化のために社内で生成AIを使いたい、用途も限定されず、さまざまなシーンで使いたい、でも、特殊な業種で、専門知識を追加しなければ使い物にならない……みたいなケース。……なんかこう、すでにシーンがかなり限定されてしまう気がしますが、投資会社で生成AIを活用するのに、アナリストのレポートや企業の財務諸表など広範囲な金融業界の知識を学習させることで、使えるようにする、という感じらしい。この場合、学習させるデータは「これが正解」みたいなラベルはないですよね。つまり、「大量のラベルなしデータを学習させる」「用途が特定されない」ことがポイント。そして、常に新しいデータを用いて継続的に学習させ続けることになります。
「業種・業界に特化したデータを使う」「ラベルもつけない」というと、RAGでよいのでは……?という疑問も出てきますが、RAGはあくまでも入力されたプロンプト(質問)をベースに答えが書いてありそうなデータを検索して使う、というものでした。私自身、AIのテキスト起こしを使ったりもするのですが、正直IT関連の用語については全然ちゃんと起こしてくれない。よくある3文字アルファベットの略語、製品・サービス名はほぼダメです。このあたり、RAGを使ってどうにかなる感じではなさそうな気がしますが、継続的事前学習で「業種・業界に特化したデータを学習させる」と、用語もちゃんと理解してテキスト起こししてくれるようになる、ということかなと理解しています。
ハードルが低いところから、まずは使ってみることが重要
生成AI活用の方法、聞いたことはあっても、なんとなく分かったふりをしておりました。RAGまではなんとかなっても、ファインチューニングとか「難しそうだし、きっと関係ない」とそっと距離を置いていました。今回、理解は深まったものの、ファインチューニングや継続的事前学習をするとなると、やっぱりかなり大変なのでは……?という印象は否めません。
ただし!もちろんいきなりハードルが高いところからチャレンジする必要はありません。生成AIだってどんどん進化していて、プロンプトエンジニアリングで十分精度が出る可能性だってあるわけです。だから、自社の用途で期待する回答が得られるかをパターン1から順に試していくのが、王道。そのうえでコストや手間やいろいろとバランスを見ながら、どこまでやるのか考えていく、ということになるのではないでしょうか?
次回は、生成AIと自社データ連携させて使うときに今もっとも現実的な選択肢と言えそうなRAGについて詳しく解説します。以上、シイノキでした!